
Google Teachable Machine 활용 프로젝트 - 졸지마!

오.오.쓰 에 오신 것을 환영합니다.
[ 졸지마 프로젝트 ] 입니다.
아래와 같은 순서로 배워보겠습니다.
1. 학습 목표
AI, deep-learning, machine-learning 등의 단어가 많이 들립니다.
단어만으로도 어렵게 느껴지는데, 6살 아이가 machine-learning을 했다고 하네요. 특별한 사람만 할 수 있는지 알았는데, 어떻게 6살 아이가 한 걸까요?
바로, 구글에서 제공한 teachable machine을 사용했기 때문이라고 합니다. 이런 내용을 보자마자 열정이 불타오릅니다. 설명을 열심히 읽으면서 공부를 하고 사용법을 익혔습니다. 사용하면서, 좋은 툴이라고 충분히 인지하였습니다. 그러나 '나의 생활 중 어떤 부분에 적용하면 좋을까?'라고 생각하는 순간 막막합니다. 여러분은 어떠세요?
아무리 좋은 툴이 있더라도, 그 툴을 활용하지 못한다면 나에겐 필요 없는 기능이 돼버립니다. 생활 속 불편함을 해결하기 위해서 이 기능을 활용해 볼 순 없을까요?
동영상 강의를 듣거나, 책을 읽을 때 본인도 모르게 잠든 적이 누구에게나 있을 거라고 생각해요. 필자는 깜빡 잠이 들었는데, 아무도 깨워주지 않아서 곤란했던 적이 한두번이 아닙니다. 그래서 조는 상태를 감지하여 알람을 주는 프로그램이 있었으면 좋겠다는 생각이 들었습니다. 일명, '졸지마 프로젝트!' [그림 2]처럼 졸고 있는 상태를 확인하고, 그 상태가 30초가 유지되면 경고음이 울리고, 카카오톡으로 잠을 깨우는 노래를 보내면 확실하게 잠을 깨울 수 있겠죠?
[구현 순서]
구글에서 제공하는 Teachable Machine으로 정상 모습인지 조는 모습인지를 판별하는 모델을 학습합니다. OpenCV를 통해서 카메라로 촬영을 합니다. 촬영된 모습이 30초 이상 조는 모습으로 유지되면, 소리로 알람을 주고 카카오 메시지를 전송합니다.
[최종 결과]
[언어 & 환경(IDE)]
Python 3.7 & Jupter notebook
[프로젝트 리소스 및 소스 코드]
- dont_sleep.ipynb : 졸지마 프로젝트 구현 코드
- kakao_utils.py : 카카오 메시지 전송을 위한 유틸리티 구현 코드 (참고 : 나에게 카카오톡 보내기)
- res/dont_sleep : 졸지마 프로젝트 리스소 파일
- res/kakao_message/kakao_token.json : 카카오 access token과 refresh token이 관리되는 파일 (참고 : x장. 나에게 카카오톡 보내기)
> 접속 URL : drive.google.com/drive/folders/10KXyPrJ_KEesvAvjnMpx1DS_md7gaN6H?usp=sharing
ai-creator 공유폴더 - Google 드라이브
drive.google.com
※ 프로젝트에 필요한 리소스 및 소스코드의 경로 구성은 자유롭게 설정하면 됩니다. 그러나, 아래 설명되어 있는 코드 구현이 제시된 구성으로 되어 있으니, 동일하게 경로와 파일명으로 구성해 둔다면 별다른 코드 수정 없이 실행해 볼 수 있습니다.
2. 사전 준비
졸지마 프로젝트를 위해서 세 가지 사전 준비가 필요합니다.
1) '나에게 카카오톡 보내기'의 사전 준비
2) 웹캠
3) 카카오 애플리케이션에 사이트 도메인 등록하기
4) 라이브러리 설치
1) 은 별다른 설명이 필요 없고, 공유된 링크를 확인하세요.
카카오 OpenAPI 활용 - 나에게 카톡 메시지 보내기
[목차] 1. 학습목표 2. 들어가기 3. 사전 준비 4. 사전 지식 쌓기 5. 구현 ㅁ Trouble Shooting ㅁ 요약정리 ㅁ 보충 자료 1. 학습목표 카카오에서 제공하는 OpenAPI를 이용해서 "나에게 카카오톡 메시지"를
ai-creator.tistory.com
2) 웹캠의 경우는 노트북에 내장되어 있어도 되고, 외장 웹캠도 가능합니다.
3) 카카오 애플리케이션에 사이트 도메인 등록하기
30초 이상 조는 모습이 유지되면, 2가지 조치를 취하려고 합니다.
첫 번째는 컴퓨터에서 소리가 나도록
두 번째는 카톡으로 메시지로 '졸음 방지 베타파' 유튜브 링크를 보내는 것입니다.
유튜브로 연결될 수 있도록 설정합니다.
| 순서 : 카카오 개발자 사이트 접속 > "내 애플리케이션" 클릭 > 앱설정 > 플랫폼 > Web에서 [수정] 버튼 클릭 > www.youtube.com 추가 |
4) 라이브러리 설치
설치가 필요한 라이브러리 목록입니다.
$ pip install opencv-python
$ pip uninstall tensorflow
$ pip install tensorflow==2.3
$ pip install beepy먼저, opencv-python입니다. 조는 모습과 정상적인 모습을 카메라를 통해 확인이 필요한데, 이를 위해 OpenCV 라이브러리를 사용합니다. OpenCV(Open Source Computer Vision)는 실시간 컴퓨터 비전을 목적으로 한 라이브러리이며, 파이썬 환경에서 사용하므로 opencv-python을 설치합니다.
다음은 tensorflow 입니다. 딥러닝 같은 기계 학습에 사용되는 라이브러리이며, Google Teachable Machine을 사용하기 위해 필요합니다. 다양한 버전이 있지만, tensorflow.keras가 지원되어야 하므로 tensorflow 2.3 버전 이상을 사용해야 합니다. (** 2020년 11월 update)
마지막으로는 beepy입니다. 조는 상태가 30초 이상 될 경우, 컴퓨터에 내장된 음악으로 소리를 냅니다.
3. 사전 지식 쌓기
졸지마 프로젝트를 수행하기 위해 지식을 쌓을 내용은 다음과 같습니다.
3-2) Google Teachable Machine 이란?
3-3) Google Teachable Machine 사용 방법
3-4) Google Teachable Machine로 모델 만들기
3-1) OpenCV로 카메라 입력받기
OpenCV란? Open Source Computer Vision의 약자로 컴퓨터 비전(Vision)을 목적으로 한 라이브러리입니다. 이미지 처리에 필요한 기능들이 많이 지원하고 있습니다.
자세한 내용은 공유된 URL 또는 OpenCV를 검색해서 더 공부해보세요.
> 접속 URL : opencv-python.readthedocs.io/en/latest/
이번 예제는 내장 또는 외장 카메라를 사용하여 촬영을 해보겠습니다.
프로그램을 실행하면 카메라를 켜지고, 작은 윈도우 창을 열리고 카메라 촬영 화면이 보여집니다.
코드
import cv2
# 카메라 캡쳐 객체, 0=내장 카메라
capture = cv2.VideoCapture(0)
# 캡쳐 프레임 사이즈 조절
capture.set(cv2.CAP_PROP_FRAME_WIDTH, 320)
capture.set(cv2.CAP_PROP_FRAME_HEIGHT, 240)
while True: # 특정 키를 누를 때까지 무한 반복
# 한 프레임씩 읽기
ret, frame = capture.read()
if ret == True:
print("read success!")
# 이미지 뒤집기, 1=좌우 뒤집기
frame_fliped = cv2.flip(frame, 1)
# 읽어들인 프레임을 윈도우창에 출력
cv2.imshow("VideoFrame", frame_fliped)
# 1ms동안 사용자가 키를 누르기를 기다림
if cv2.waitKey(1) > 0:
break
# 카메라 객체 반환
capture.release()
# 화면에 나타난 윈도우들을 종료
cv2.destroyAllWindows()실행 결과
윈도우 작업표시줄에 python 윈도우 창이 생겼습니다.
클릭을 하면, 카메라로 촬영된 영상이 화면에 보입니다.
python 윈도우 창에 아무키를 누르면, 촬영을 멈추고 윈도우 창이 종료됩니다.
코드 설명
1라인 : 필요한 라이브러리를 import 합니다.
4라인 : 카메라 객체를 생성합니다. cv2.VideoCapture()의 input 인자는 0인 경우는 내장 카메라를, 1인 경우는 외장 카메라를 의미합니다. 노트북에 있는 기본 카메라를 사용할 경우 0으로 세팅하면 됩니다.
7~8라인 : 캡처 프레임 사이즈 조절합니다. width=320, height=240입니다. 단위는 픽셀(pixel)입니다.
10라인 : 키보드로 특정 키가 눌릴 때까지 무한 반복하는 반복문입니다.
12라인 : 비디오의 한 프레임씩을 읽습니다. 프레임을 읽기를 성공하면 ret값이 True, 실패하면 False가 나타납니다. frame에는 읽은 비디오 프레임이 담겨 있습니다.
17라인 : cv2.flip()으로 이미지를 뒤집습니다. input인자에서 frame은 캡처한 프레임이고, 1은 좌우 뒤집기를 의미합니다.
20라인 : 읽어 들인 프레임을 윈도우창에 출력합니다.
23~24라인 : 1ms 동안 기다리면서 키보드로 특정 키가 눌려지는지 확인합니다. 만약 눌려졌다면, 24라인에 있는 break로 무한 반복문을 빠져나옵니다.
27라인 : 카메라 객체를 반환합니다.
30라인 : python 윈도우 창을 닫습니다.
OpenCV를 통해서 카메라로 촬영을 해보니 재밌죠? OpenCV는 이미지, 영상과 관련된 기능들을 많이 지원하고 있습니다. 흑백으로도 변경할 수 있고, 녹화도 할 수 있어요. 다양한 곳에서 활용해 보세요.
3-2) Google Teachable Machine 이란?
> Google Teachable Machine 공식 홈페이지 : https://teachablemachine.withgoogle.com/
Google Teachable Machine의 단어를 하나씩 확인해봅시다.
- Google : 구글에서 만든 Tool입니다.
- Teachable : 가르치는 / 잘 배우는
- Machine : 기계
를 의미합니다.
[그림 8]에서도 알 수 있듯이 이미지, 음성, 자세를 인식하기 위해 컴퓨터를 훈련시킬 수 있는 기능입니다. 여기까지는 이해가 잘 되시죠?
그다음 줄에는 쉽고 빠르게, machine learning model을 만들 수 있다고 합니다.
그럼 'machine learning'이란 의미를 알아보시죠. 단어 뜻 그대로 '기계 학습'이라는 의미입니다. 즉, '기계가 스스로 학습하는 기술'입니다. 기계는 어떻게 학습을 할까요? 기계도 사람과 동일하게 학습을 합니다. 어린아이들이 단어를 공부하는 모습을 상상해 봅시다. 부모님들은 아래와 같은 그림 카드를 보여주고 단어를 알려줍니다.
'이렇게 생긴 건 수박이고, 저렇게 생긴건 참외야'를 반복해서 말해주죠. 정말 많이 반복을 합니다. 이런 과정을 학습(train)이라고 하죠. 그러고 나서, 그림만 보여주고 '이게 뭐야?'라고 물어보고, 아이는 '수박' 또는 '참외'라고 대답을 합니다. 그 후 맞으면 칭찬하고, 틀리면 다시 알려주죠.
기계도 비슷한 과정을 거칩니다. 먼저 학습(train)을 합니다. 수박이 그려진 이미지를 준비하고, 수박이라고 알려줍니다. 참외도 마찬가지로요. 반복문을 사용하여 여러 차례 반복해서 알려줍니다. 그리고 어느 정도 학습이 되었다고 생각이 될 때, 기계에게 '수박'/'참외'를 구별할 수 있는지 물어봅니다. 이런 과정을 추론(inference)이라고 합니다.
즉, machine learning은 기계가 학습을 하다는 의미를 가집니다. 그리고, 학습된 내용이 사람들은 뇌에 가지고 있듯 기계의 경우는 숫자로 이루어진 값들이 존재하고 그 저장본을 model이라고 합니다.
정리하면, Google Teachable Machine은 기계가 학습하는 과정을 쉽고 빠르게 하도록 도와주며, 최종적으로 학습이 완료된 model을 제공하는 툴입니다.
3-3) Google Teachable Machine 사용 방법
Google Teachable Machine 사용법은 간단합니다.
아래 그림을 보세요. 3단계로 이루어지네요.
1단계 Gather : 컴퓨터가 학습을 하기 위한 데이터를 모읍니다.
2단계 Train : 컴퓨터가 학습을 합니다.
3단계 Export : 학습을 마친 후 model을 다운로드합니다.
Google Teachable Machine에서 제공하는 문서를 보면서 사용해 보면 느껴지겠지만, 직관적으로 구성이 되어 있어 정말 6살 아이도 할 수 있을 정도입니다.
3-4) Google Teachable Machine로 모델 만들기
Google Teachable Machine을 사용해보겠습니다. 갑자기 펭수와 펭귄을 기계가 구분할 수 있을지 궁금해지네요. 펭수와 펭귄을 구분하는 모델을 만들어보겠습니다.
먼저, 공식 홈페이지 (teachablemachine.withgoogle.com/)에 접속하여 [Get Started] 버튼을 클릭합니다.
Image, Audio, Pose 3가지 종류의 프로젝트를 지원합니다. 그중에서 Image Project를 선택합니다.
'3-3) Google Teachable Machine 사용 방법'의 설명처럼 아래와 같은 순서를 가집니다.
1단계 Gather -> 2단계 Train -> 3단계 Export입니다.
1단계 Gather
컴퓨터가 학습을 할 수 있도록 펭수와 펭귄 사진을 준비합니다. 연예인 사진 모으기 프로젝트에서(Link) 구현한 코드를 사용하여 펭수와 펭귄 사진을 쉽게 모을 수 있습니다. 다운로드 받은 파일은 res/dont_sleep/펭귄과 펭수 사진 모음 폴더에 넣어두었으니, 필요시 사용하세요.
준비가 되었다면, [업로드] 버튼을 클릭하고, 사진을 업로드합니다. 그 후 'Class 1'을 '펭귄'으로 수정합니다.


Class2도 동일한 방법으로 펭수사진을 업로드하고, '펭수'로 이름을 변경합니다.

[그림 16] 펭수 사진 업로드 후 Class 2를 펭수로 변경
2단계 Train
[Train Model] 버튼을 클릭하여 학습을 진행합니다.
점점 진행이 되면서(progress bar 확인) 조금 기다리면 학습이 완료됩니다.
3단계 Export
모델을 다운로드하여서 프로그램으로 만들 수 있지만, 여기서는 모델이 잘 동작하는지만 확인해보도록 하겠습니다.
[File] 버튼 클릭한 후, 학습 때 사용하지 않은 이미지를 업로드합니다. 하단에 보면 기계가 구분한 결과가 나옵니다. '펭귄'이라고 100% 확신을 하네요. 대단합니다.
혹시 모르니, 펭수로 한번 더 확인해보겠습니다.
이번에도 역시 한 번도 학습한 적 없는 펭수 사진을 사용하였습니다. 기계가 '펭수'라고 100% 확신했네요.
몇 번의 클릭만으로 펭수와 펭귄을 기계가 판단할 수 있게 되었습니다. 정말 6살도 사용할 수 있을 정도로 쉽고, 편리하죠?
4. 구현
졸지마 프로젝트를 구현해 보겠습니다.
구현할 순서는 다음과 같습니다. 구글에서 제공하는 Teachable Machine으로 정상적인 모습인지 조는 모습인지를 알려주는 모델을 학습합니다. OpenCV를 통해서 카메라 촬영을 합니다. 30초 이상 조는 모습이 유지되면, 소리로 알람을 주고 카카오 메시지를 전송합니다.
[구현 순서]
점진적으로 구현을 완성해 갈 수 있도록 Step1 > Step2 > Step3 순서로 진행되며, Step3에서는 소스코드를 완성합니다.
| Step1 | 조는 모습을 판별하는 모델 생성하기 |
| Step2 | 잠깨는 방법 설정 |
| Step3 | 카메라로 조는 상태 감지하기 |
Step1) 조는 모습을 판별하는 모델 생성하기
|
> 순서 : Teachable Machine 사이트(teachablemachine.withgoogle.com/) 접속 > [Get Started] 클릭 > [Image Project] 클릭으로 아래와 같은 화면까지 이동합니다. 참고) 3-4) Google Teachable Machine로 모델 만들기 |
이번에는 [Webcam]을 이용해 보겠습니다. [Webcam] 버튼을 누르면, 브라우저에 따라 카메라 접근 권한을 허용할 것인지 확인 요청을 합니다. 허용을 누릅니다. 그럼, 웹캠이 켜졌다 의미로 불이 켜집니다.


teachable machine에 webcam으로 촬영되는 화면이 보이게 됩니다.
정상(졸지 않은) 모습과 졸고 있는 모습 총 2가지 종류로 이미지를 생성할 예정입니다.
Class1은 정상 모습으로 [Hold to Record] 버튼을 눌러 촬영합니다.
좌/우로 고개를 돌리는 모습도 정상 모습이니 촬영하면서, 정상 모습에 해당하는 이미지를 100장 이상 저장합니다.

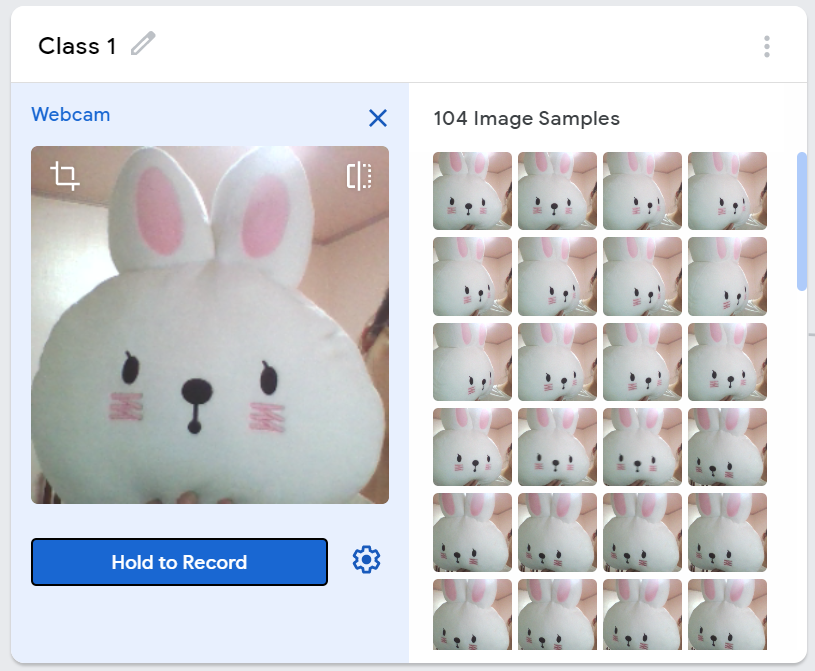
Class2는 졸는 모습으로 자유롭게 총 100장 이상의 이미지를 저장합니다. 토끼가 잠들면, 고개를 떨구니 귀만 보이는 모습으로 촬영하였습니다.
Train Model 버튼을 눌러 학습을 시킵니다.

일정 시간이 지나면, 학습이 완료됩니다.
학습이 완료되었다면, Preview를 통해 두 가지 경우를 테스트해 봅니다. 잘 동작하는 것을 확인하고, Export Model을 눌러 모델을 다운로드합니다.
※ 만약 원하는 대로 동작하지 않았다면, 이미지 파일이 적은 것이 원인일 수도 있습니다. 이미지 파일을 늘리고, 모습을 좀 더 정확하게 합니다.


판별이 원하는 바대로 잘 될 경우, Tensorflow > Download my model로 모델을 다운로드합니다. 아주 친절하게도 테스트를 위한 소스코드도 준비해두었네요.
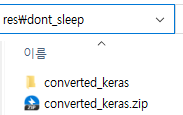
다운로드한 파일은 converted_keras.zip이라는 이름을 가지며, 리소스를 관리하는 폴더로 복사하여 압축을 해제합니다. 이 책에서는 res/dont_sleep 폴더에 압축을 풀었고요, converted_keras 폴더로 들어가 보니 2개의 파일이 있습니다.
1) keras_model.h5는 학습이 완료된 모델 파일이고,
2) labels.txt 파일을 열어보니 class1 (정상모습)은 0을 의미하고, class2 (조는 모습)은 1을 의미한다는 label값이 적혀 있네요.
모델 다운로드를 하였으니, Webcam이 off될 수 있도록 Preview의 Input을 off로 변경합니다.
이제는 [그림 31] 학습이 완료된 모델 파일 다운로드에서 공유된 예제 코드를 살펴보시죠.
주의 깊게 보고 넘어가야 할 부분이 있습니다.
코드
import tensorflow.keras
from PIL import Image, ImageOps
import numpy as np
# Disable scientific notation for clarity
np.set_printoptions(suppress=True)
# Load the model
model = tensorflow.keras.models.load_model('keras_model.h5')
# Create the array of the right shape to feed into the keras model
# The 'length' or number of images you can put into the array is
# determined by the first position in the shape tuple, in this case 1.
data = np.ndarray(shape=(1, 224, 224, 3), dtype=np.float32)
# Replace this with the path to your image
image = Image.open('test_photo.jpg')
#resize the image to a 224x224 with the same strategy as in TM2:
#resizing the image to be at least 224x224 and then cropping from the center
size = (224, 224)
image = ImageOps.fit(image, size, Image.ANTIALIAS)
#turn the image into a numpy array
image_array = np.asarray(image)
# display the resized image
image.show()
# Normalize the image
normalized_image_array = (image_array.astype(np.float32) / 127.0) - 1
# Load the image into the array
data[0] = normalized_image_array
# run the inference
prediction = model.predict(data)
print(prediction)
14라인, 22라인에서 이미지 사이즈를 244x244로 변경했습니다. 모델에서 244x244인 이미지로 학습을 하였으므로, 추론을 할 때도 동일한 사이즈로 준비되어야 합니다.
31라인은 이미지를 normalization을 했네요. normarlization이 무엇인지는 알 수 없지만, '필요하다' 정도만 생각해주시고, 궁금하신 분들은 검색을 통해서 더 깊게 확인해보세요.
9라인은 학습된 모델을 로딩하는 방법입니다. tensorflow.keras.models.load_model()를 호출하고, input 인자로 모델 파일명을 설정해줍니다. 다운로드한 모델 파일의 경로로 코드를 변경하면 됩니다.
39라인은 예측하는 코드입니다.
그럼, 9라인을 다운로드하여둔 모델 파일로 변경을 하고, 17라인은 테스트하고 싶은 이미지 파일로 수정합니다. 그리고 테스트해보고, 결괏값만 확인해보세요.
다운로드한 모델과 해당 테스트 파일로 결과를 확인하니, prediction의 값이 이렇게 나옵니다.
[[0.9996804 0.00031962]]
결괏값은 확률을 의미합니다. 또, 이차원 배열이니 prediction[0, 0] 을 하면 class1의 확률인 0.9996804 값이, prediction[0, 1]을 하면, class2의 확률인 0.00031962이 추출됩니다.
Step2) 잠 깨는 방법 설정
30초 이상 조는 모습이 유지되면, 잠깨는 방법으로 2가지 조치를 취하려고 합니다.
첫 번째는 컴퓨터에서 소리가 나도록
두 번째는 카톡으로 메시지로 '졸음 방지 베타파' 유튜브 링크를 보내는 것입니다.
코드
import beepy
import kakao_utils
# 컴퓨터에 내장된 소리를 출력
def beepsound():
beepy.beep(sound=6)
# 카카오톡 메시지로 '졸음 방지 베타파' 영상 링크를 전송
def send_music_link():
KAKAO_TOKEN_FILENAME = "res/kakao_message/kakao_token.json"# "<kakao_token.json 파일이 있는 경로를 입력하세요.>"
KAKAO_APP_KEY = "<REST_API 앱키를 입력하세요>"
tokens = kakao_utils.update_tokens(KAKAO_APP_KEY, KAKAO_TOKEN_FILENAME)
# 텍스트 메시지 보내기
template = {
"object_type": "text",
"text": "당신은 30초 이상 졸았습니다. 졸지 마세요!!!!",
"link": {
"web_url": "https://www.youtube.com/watch?v=7Q2N7919o5o",
"mobile_web_url": "https://www.youtube.com/watch?v=7Q2N7919o5o"
},
"button_title": "잠깨는 노래 듣기"
}
# 카카오 메시지 전송
res = kakao_utils.send_message(KAKAO_TOKEN_FILENAME, template)
if res.json().get('result_code') == 0:
print('텍스트 메시지를 성공적으로 보냈습니다.')
else:
print('텍스트 메시지를 보내지 못했습니다. 오류메시지 : ', res.json())
실행 결과
beepsound()를 호출하면, 컴퓨터에 내장된 소리가 출력됩니다.
send_music_link()를 호출하면, 아래와 같은 메시지가 전송됩니다.
코드 설명
1~2라인 : 필요한 라이브러리를 import 합니다.
5~6라인 : 컴퓨터에 내장된 소리를 출력하는 함수입니다. 6라인에 beepy.beep(sound=6)에 숫자를 바꾸어 다른 소리도 들어보세요. 그리고, 잠을 확~깰 수 있는 소리로 변경해보세요.
9~31라인 : text형태이고, 버튼에 유튜브 링크가 있어 클릭 시 음악을 들려줄 수 있게 합니다. 카카오 메시지 템플릿을 구현하고, 카카오톡 메시지를 보내는 함수입니다.
Step3) 카메라로 조는 상태 감지하기
'2-1) OpenCV로 카메라 입력받기' 에서 배운 내용을 바탕으로 카메라로 현재 상태를 촬영합니다. 그리고, 촬영된 프레임을 학습 모델에 input으로 주어 조는 상태인지 정상 상태인지를 확인합니다.
코드
import cv2
import tensorflow.keras
import numpy as np
## 이미지 전처리
def preprocessing(frame):
# 사이즈 조정
size = (224, 224)
frame_resized = cv2.resize(frame, size, interpolation=cv2.INTER_AREA)
# 이미지 정규화
frame_normalized = (frame_resized.astype(np.float32) / 127.0) - 1
# 이미지 차원 재조정 - 예측을 위해 reshape 해줍니다.
frame_reshaped = frame_normalized.reshape((1, 224, 224, 3))
return frame_reshaped
## 학습된 모델 불러오기
model_filename = 'res/dont_sleep/converted_keras/keras_model.h5'
model = tensorflow.keras.models.load_model(model_filename)
# 카메라 캡쳐 객체, 0=내장 카메라
capture = cv2.VideoCapture(0)
# 캡쳐 프레임 사이즈 조절
capture.set(cv2.CAP_PROP_FRAME_WIDTH, 320)
capture.set(cv2.CAP_PROP_FRAME_HEIGHT, 240)
sleep_cnt = 1 # 30초간 "졸림" 상태를 확인하기 위한 변수
while True:
ret, frame = capture.read()
if ret == True:
print("read success!")
# 이미지 뒤집기
frame_fliped = cv2.flip(frame, 1)
# 이미지 출력
cv2.imshow("VideoFrame", frame_fliped)
# 1초마다 검사하며, videoframe 창으로 아무 키나 누르게 되면 종료
if cv2.waitKey(200) > 0:
break
# 데이터 전처리
preprocessed = preprocessing(frame_fliped)
# 예측
prediction = model.predict(preprocessed)
#print(prediction) # [[0.00533728 0.99466264]]
if prediction[0,0] < prediction[0,1]:
print('졸림 상태')
sleep_cnt += 1
# 졸린 상태가 30초간 지속되면 소리 & 카카오톡 보내기
if sleep_cnt % 30 == 0:
sleep_cnt = 1
print('30초간 졸고 있네요!!!')
beepsound()
send_music_link()
break ## 1번만 알람이 오면 프로그램을 정지 시킴 (반복을 원한다면, 주석으로 막기!)
else:
print('깨어있는 상태')
sleep_cnt = 1
# 카메라 객체 반환
capture.release()
# 화면에 나타난 윈도우들을 종료
cv2.destroyAllWindows()
실행 결과
read success!
깨어있는 상태
read success!
깨어있는 상태
read success!
깨어있는 상태
... (생략)...
read success!
졸림 상태
read success!
졸림 상태
30초간 졸고 있네요!!!
코드 설명
1~3라인 : 필요한 라이브러리를 import 합니다.
6~17라인 : 추론을 하기 전에 이미지를 전처리를 하는 함수를 정의합니다. input인자는 카메라로부터 입력받은 frame이 전송됩니다. 244x244로 사이즈를 조정하고, 12라인에서 정규화도 진행해줍니다. 이런 전처리 과정이 완료된 frame을 output으로 줍니다. 처리 이유에 대해서는 'Step1) 조는 모습을 판별하는 모델 생성하기' 의 제일 마지막 설명을 확인하세요.
20~21라인 : 학습한 모델을 읽어옵니다.
24~44라인 : '3-1) OpenCV로 카메라 입력받기' 에서 설명한 코드와 동일합니다.
47라인 : 카메라로 입력받은 프레임을 전처리를 합니다.
50라인 : 조는 상태인지, 아닌지를 판별하기 위한 추론을 합니다.
53라인 : prediction[0,0]은 class1의 확률을 의미하고, prediction[0,1]은 class2의 확률을 의미합니다. 즉, class2의 확률값이 크면 졸고 있는 상태라고 여깁니다. 졸때 마다 소리를 낼 수는 없으니, 30초간 지속될 경우만 처리합니다.
58~63라인 : 30초간 지속된 경우이므로, beepsound()를 호출하여 컴퓨터에 내장된 소리를 출력하고, send_music_link()를 호출하여 카카오 메시지로 음악 링크를 전달합니다.
63라인에 break문이 있어 한번 조건을 만족하면 무한반복을 종료하게 되는데, 반복 수행을 원할 시 주석처리를 해주면 됩니다.
69~71라인 : 카메라 객체 반환 및 윈도우 창을 종료합니다.
이렇게 졸지마 프로젝트가 완성이 되었습니다.
5. 요약정리
조는 상태를 감지하여, 알람을 받는 졸지마 프로젝트를 진행해 보았습니다.
조는 상태인지, 아닌지는 구글에서 제공해주는 딥러닝 알고리즘을 이용했는데요, 구글에서 teachable machine을 제공해줌으로써 어려운 딥러닝 모델을 아주 쉽게 만들 수 있었습니다. 정말 6살 짜리도 만들 수 있겠죠?
모델에서 예측해 준 값을 통해서 조는 모습이 지속된 경우 알람을 전달하여 잠을 깨워 보았습니다.
teachable machine이 image 프로젝트로도 더 다양한 프로젝트를 진행해 볼 수 있습니다. 코로나로 인해서 마스크 착용 여부를 감지하는 모델을 만들 수 있고, 나의 얼굴인지를 인식하는 모델을 만들어 현관문 출입에 사용할 수도 있습니다. 또한 pose와 sound에 관련된 프로젝트도 진행해보세요. 기술이 문제가 아니라, 아이디어 싸움임을 여실히 느끼실 수 있을 것입니다.
ㅁ Trouble Shooting
1) tensorflow.keras.models.load_model() 호출시 아래와 같은 에러가 발생한다면?
에러
| c:\users\seong\appdata\local\programs\python\python37\lib\site-packages\tensorflow\python\keras\engine\sequential.py in from_config(cls, config, custom_objects) 396 for layer_config in layer_configs: 397 layer = layer_module.deserialize(layer_config, --> 398 custom_objects=custom_objects) 399 model.add(layer) 400 if (not model.inputs and build_input_shape and c:\users\seong\appdata\local\programs\python\python37\lib\site-packages\tensorflow\python\keras\layers\serialization.py in deserialize(config, custom_objects) 107 module_objects=globs, 108 custom_objects=custom_objects, --> 109 printable_module_name='layer') c:\users\seong\appdata\local\programs\python\python37\lib\site-packages\tensorflow\python\keras\utils\generic_utils.py in deserialize_keras_object(identifier, module_objects, custom_objects, printable_module_name) 360 config = identifier 361 (cls, cls_config) = class_and_config_for_serialized_keras_object( --> 362 config, module_objects, custom_objects, printable_module_name) 363 364 if hasattr(cls, 'from_config'): c:\users\seong\appdata\local\programs\python\python37\lib\site-packages\tensorflow\python\keras\utils\generic_utils.py in class_and_config_for_serialized_keras_object(config, module_objects, custom_objects, printable_module_name) 319 cls = get_registered_object(class_name, custom_objects, module_objects) 320 if cls is None: --> 321 raise ValueError('Unknown ' + printable_module_name + ': ' + class_name) 322 323 cls_config = config['config'] ValueError: Unknown layer: Functional |
원인
tensorflow 2.3에서 빌드된 모델은 하위버전에서 load가 안된다. 2020년 11월에 구글 티쳐블머신이 tesorflow버전은 업데이트한 환경에서 빌드된 모델이 배포 되는 것 같다. 그래서 기존 tensorflow를 삭제하고, 2.3버전으로 업그레이드를 하면 문제가 해결된다.
해결방법
$ pip uninstall tensorflow
$ pip install tensorflow==2.3
도움이 되셨다면, 좋아요 / 구독 버튼 눌러주세요~
저작물의 저작권은 작성자에게 있습니다.
공유는 자유롭게 하시되 댓글 남겨주세요~
상업적 용도로는 무단 사용을 금지합니다.
끝까지 읽어주셔서 감사합니다^^