
[머신러닝 기초] 지도학습 - classification 평가척도 (confusion matrix, accuracy, recall, precision, f1-score, ROC, AUC)
목차
1. 오차행렬 (Confusion Matirx)
2. 평가 지표
2-1) Accuracy, Precision, Recall
2-2) F1-Score
2-3) ROC Curve와 AUC
1. 오차행렬 (Confusion Matrix)
의미
알고리즘이 예측을 수행하면서 얼마나 헷갈리고(confused) 있는지 보여지는 지표이다.

매우 혼란스러운 행렬이지만, 모든 값은 "예측"이 기준이다.
| True Negative (TN) | 맞췄다. Negative로 예측해서 | |
| False Positive (FP) | 틀렸다. Positive로 예측해서 | 실제는 Negative |
| False Negative (FN) | 틀렸다. Negative로 예측해서 | 실제는 Positive |
| True Positive (TP) | 맞췄다. Positive로 예측해서 |
Sklearn API
이를 위해 sklearn에서는 API를 지원한다.
| 목적 | import | API |
| 오차행렬 | from sklearn.metrics import confusion_matrix | confusion_matrix() |
코드에서 보면,
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test , pred)
2. 평가지표
2-1) Accuracy, Precision, Recall
- 정확도 (Accuracy)
- 정밀도 (Precision)
- 재현율 (Recall)
의미
각 지표는 0~1 사이의 값을 가지며, 1에 가까울수록 '잘 분류하는 알고리즘'을 의미한다.
그렇다면,
- 재현율(recall)은 FN을 낮추는데,
- 정밀도(precision)는 FP를 낮추는데
초점을 맞춘다.
재현율(recall)의 FN을 낮춘다는 것은
"Negative라고 잘못 예측하지 않도록 하겠다" = "실제 Positive"를 잘 분리해야 한다.
즉, "실제 Positive"를 잘못 판단하면 문제가 생기는 경우에 사용하는 지표이다.
예를들어 코로나 환자를 판별한다고 하자. 이때 실제 코로나 환자를 양성(Positive)이라고 잘 분리해 내야 한다. 실제코로나 환자를 음성(Negative)라고 잘못 예측하면 큰일이다. 이는 보험사기, 금융사기 또한 마찬가지다.
정밀도(precision)의 FP를 낮춘다는 것은
"Positive라고 잘못 예측하지 않도록 하겠다" = "실제Negative"를 잘 분리해야 한다.
즉, "실제 Negative"를 잘못 판단하면 문제가 생기는 경우에 사용하는 지표이다.
예를들어 스팸메일을 분류한다고 하자. 이때 실제 스팸(Positive)을 잘 걸러내는 것보다는 정상적인 메일(Negative)을 스팸으로 분리하면 문제가 생긴다. 왜? 스팸메일함에 들어간 정상메일은 아에 읽지를 못하기 때문이다.
참고) 예측에서 궁금한 것을 positive로 설정한다. 즉, 코로나는 양성을 positive로, 스팸메일 분류에서는 스팸메일을 positive로 설정한다.
Sklearn API
이를 위해 sklearn에서는 API를 지원한다.
| 목적 | import | API |
| 평가 지표 (accuracy, precision, recall) | from sklearn.metrics import accuracy_score from sklearn.metrics import precision_score from sklearn.metrics import recall_score |
accuracy_score() precision_score() recall_score() |
코드에서 보면,
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
print("정확도:", accuracy_score(y_test, pred))
print("정밀도:", precision_score(y_test, pred))
print("재현율:", recall_score(y_test, pred))
2-1-2) 재현율(recall)과 정밀도(precsion)는 trade-off
두 지표는 한쪽이 커지면, 다른 한쪽이 작아지는 경향을 띈다. 이를 trade-off 라고 한다.
코로나 검진 키트를 사용해서 수치가 0.5이상이 나면 '양성' / 이하면 '음성'이라고 판단했다고 해보자.
여기에서 기준값인 0.5를 임곗값(thresholds)라고 한다. 이 임계값을 달리하면, 양성의 비율과 음성의 비율이 달라지게 된다.

즉, 임곗값(thresholds)을 0.2정도로 낮추면, 양성으로 predict 된 값은 많아지지만 actual 양성의 비율은 상대적으로 낮아질 수 있다.
이렇듯 임곗값(thresholds) 조정에 의해 정밀도, 재현율은 trade-off관계를 갖는다.
임곗값(thresholds)를 낮추면 모두 양성이 되고 재현율이 1이 된다 (100%)
반대로 임곗값(thresholds)를 높이면 모두 음성이 되고 정밀도는 1이 된다 (100%)
그래서 재현율(recall) 또는 정밀도(precision) 한가지의 수치를 보는 것은 옳지 않으며,
업무 도메인에 맞춰 임곗값(thresholds)를 조절하면서 다양한 평가지표를 통해 최적의 알고리즘을 선택하는 것이 중요한 일이다.
2-2) F1-Score
F1-Score는 재현율과 정밀도를 결합하여 한개의 지표값으로 표현한 것이다.
재현율과 정밀도의 '조화평균'이다.
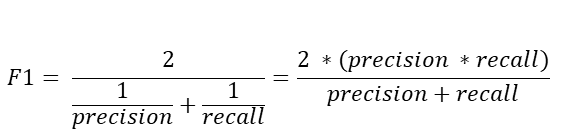
Sklearn API
이를 위해 sklearn에서는 API를 지원한다.
| 목적 | import | API |
| 평가 지표 (F1-Score) | from sklearn.metrics import f1_score | f1_score() |
코드에서 보면,
from sklearn.metrics import f1_score
print('F1 스코어: ', f1_score(y_test , pred))
2-3) ROC Curve와 AUC
- ROC Curve : Receiver Operating Characteristic Curve
- AUC : Area Under the ROC Curve
AUC는 ROC 그래프의 밑부분 면적을 의미하며, 넓을수록 '잘 분류하는 알고리즘'을 의미한다.

ROC Curve는 FPR(False Positive Rate)이 작은 상태에서 얼마나 큰 TPR(True Positive Rate)을 얻을 수 있느냐가 관건이다. 완벽한 모형을 의미하는 파란색 화살표 방향으로 가는 것이 '잘 분류하는 알고리즘'을 의미한다.

ROC Curve는 FPR을 0~1까지 변경하면서, TPR의 변화값을 구한다. FPR을 변경하는 방법은 임계값(thresholds)를 변경하면서 테스트를 진행한다.
일반적으로 덜 정확한(0.5 < AUC ≤ 0.7), 정확한(0.7 < AUC ≤ 0.9), 매우 정확한(0.9 < AUC < 1) 그리고 완벽한 모형(AUC = 1)으로 분류할 수 있다.
ROC Curve를 그려 모형간 비교가 가능하며, 그림의 경우 Model A가 더 높은 분류 성과를 가지는 것으로 판단하게 된다.
Sklearn API
이를 위해 sklearn에서는 API를 지원한다.
| 목적 | import | API |
| 평가 지표 (ROC, AUC) | from sklearn.metrics import roc_curve from sklearn.metrics import roc_auc_score |
roc_curve() roc_auc_score() |
코드에서 보면,
from sklearn.metrics import roc_auc_score
roc_score = roc_auc_score(y_test, pred_proba)
print('AUC : ', roc_auc_score(y_test, pred_proba))