데이터 분석/왕초보를 위한 머신러닝
[머신러닝 기초] 하이퍼파라메터 튜닝을 쉽게! - GridSearchCV
ai-creator
2021. 10. 16. 10:12
반응형
- 하이퍼파라미터는 머신러닝 알고리즘을 구성하는 주요 구성 요소
이 값을 조정해 알고리즘의 예측 성능을 개선 할 수 있음
Sklearn API
교차검증과 최적의 하이퍼파라메터 튜닝을 한번에 할 수 있다.
이를 위해 sklearn에서는 API를 지원한다.
| 목적 | import | API |
| 교차검증 및 하이퍼파라메터 튜닝 | from sklearn.model_selection import GridSearchCV | DecisionTreeClassifier() |
코드에서 보면,
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
# 데이터 로딩
iris_data = load_iris()
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state=121)
# 알고리즘
dtree = DecisionTreeClassifier()
### parameter 들을 dictionary 형태로 설정
parameters = {'max_depth':[1,2,3], 'min_samples_split':[2,3]}
print(parameters)
# param_grid의 하이퍼 파라미터들을 3개의 train, test set fold 로 나누어서 테스트 수행 설정.
### refit=True 가 default 임. True이면 가장 좋은 파라미터 설정으로 재 학습 시킴.
grid_dtree = GridSearchCV(dtree, param_grid=parameters, cv=3, refit=True)
# 붓꽃 Train 데이터로 param_grid의 하이퍼 파라미터들을 순차적으로 학습/평가 .
grid_dtree.fit(X_train, y_train)
# GridSearchCV 결과 추출하여 DataFrame으로 변환
scores_df = pd.DataFrame(grid_dtree.cv_results_)
scores_df[['params', 'mean_test_score', 'rank_test_score', \
'split0_test_score', 'split1_test_score', 'split2_test_score']]결과
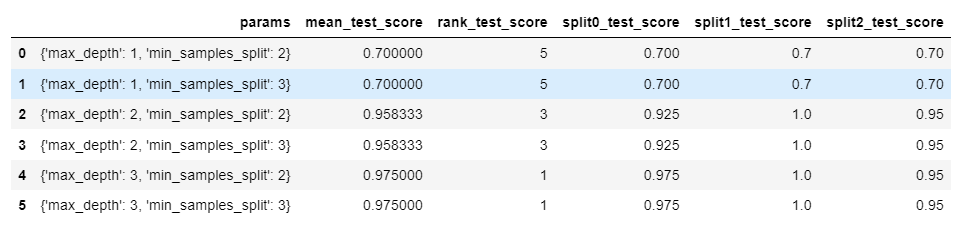
print('GridSearchCV 최적 파라미터:', grid_dtree.best_params_)
print('GridSearchCV 최고 정확도: {0:.4f}'.format(grid_dtree.best_score_))
# GridSearchCV의 refit으로 이미 학습이 된 estimator 반환
estimator = grid_dtree.best_estimator_
# GridSearchCV의 best_estimator_는 이미 최적 하이퍼 파라미터로 학습이 됨
pred = estimator.predict(X_test)
print('테스트 데이터 세트 정확도: {0:.4f}'.format(accuracy_score(y_test,pred)))결과
GridSearchCV 최적 파라미터: {'max_depth': 3, 'min_samples_split': 2}
GridSearchCV 최고 정확도: 0.9750
테스트 데이터 세트 정확도: 0.9667
ㅁ 추가학습
https://ai-creator.tistory.com/574?category=892714
[머신러닝 기초] 지도학습 - 맛보기 (w/사이킷런)
최종 목표 지도학습에서 최종목표는 titanic 데이터를 이용하여 생존여부를 예측하는 코드를 이해하는 것이다. 코드 이해에 있어 - 지도학습 수행을 위한 프로세스를 이해한다. - 프로세스의 각
ai-creator.tistory.com
다시 처음으로 돌아가, 타이타닉 소스 코드를 이해해보자.
ㅁ Reference
- [책] 파이썬 머신러닝 완벽가이드
- [블로그] 파이썬 머신러닝 완벽가이드 정리본 (Link)
- [소스코드 출처] : https://github.com/wikibook/pymldg-rev
반응형