import pandas as pd
import glob ,os
# 아래는 제 컴퓨터에서 압축 파일을 풀어 놓은 디렉토리이니, 여러분의 디렉토리를 설정해 주십시요
path = './OpinosisDataset1.0/OpinosisDataset1.0/topics'
# path로 지정한 디렉토리 밑에 있는 모든 .data 파일들의 파일명을 리스트로 취합
all_files = glob.glob(os.path.join(path, "*.data"))
filename_list = []
opinion_text = []
# 개별 파일들의 파일명은 filename_list 리스트로 취합,
# 개별 파일들의 파일내용은 DataFrame로딩 후 다시 string으로 변환하여 opinion_text 리스트로 취합
for file_ in all_files:
# 개별 파일을 읽어서 DataFrame으로 생성
df = pd.read_table(file_,index_col=None, header=0,encoding='latin1')
# 절대경로로 주어진 file 명을 가공. 만일 Linux에서 수행시에는 아래 \\를 / 변경. 맨 마지막 .data 확장자도 제거
filename_ = file_.split('\\')[-1]
filename = filename_.split('.')[0]
#파일명 리스트와 파일내용 리스트에 파일명과 파일 내용을 추가.
filename_list.append(filename)
opinion_text.append(df.to_string())
# 파일명 리스트와 파일내용 리스트를 DataFrame으로 생성
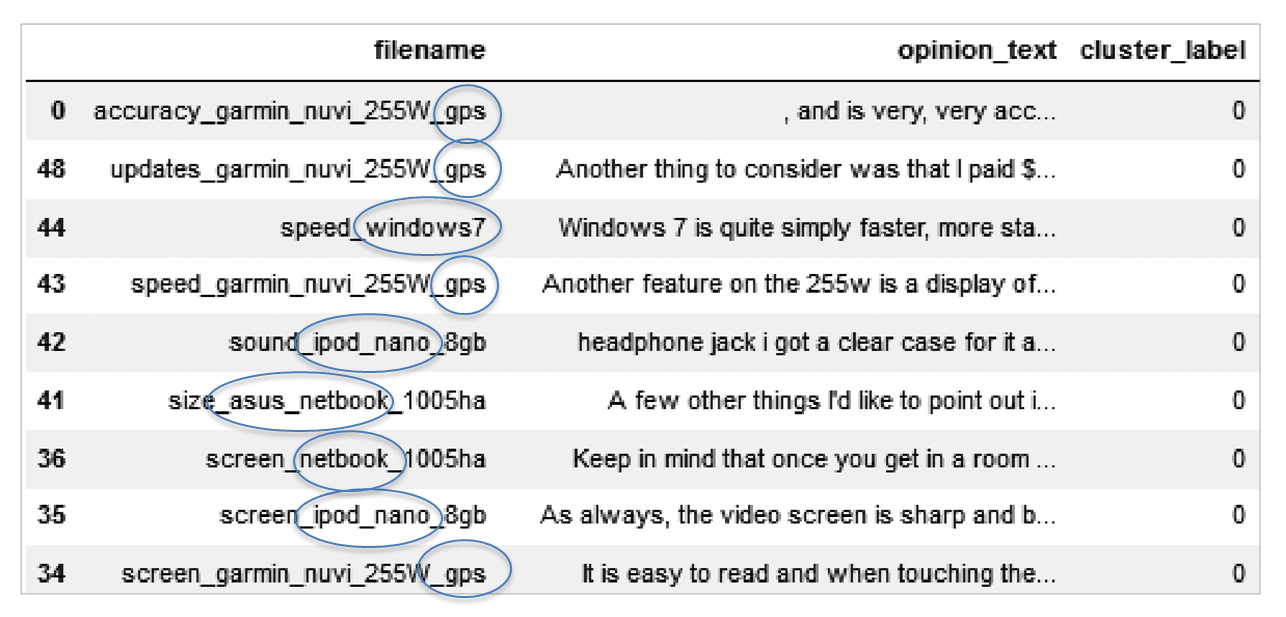
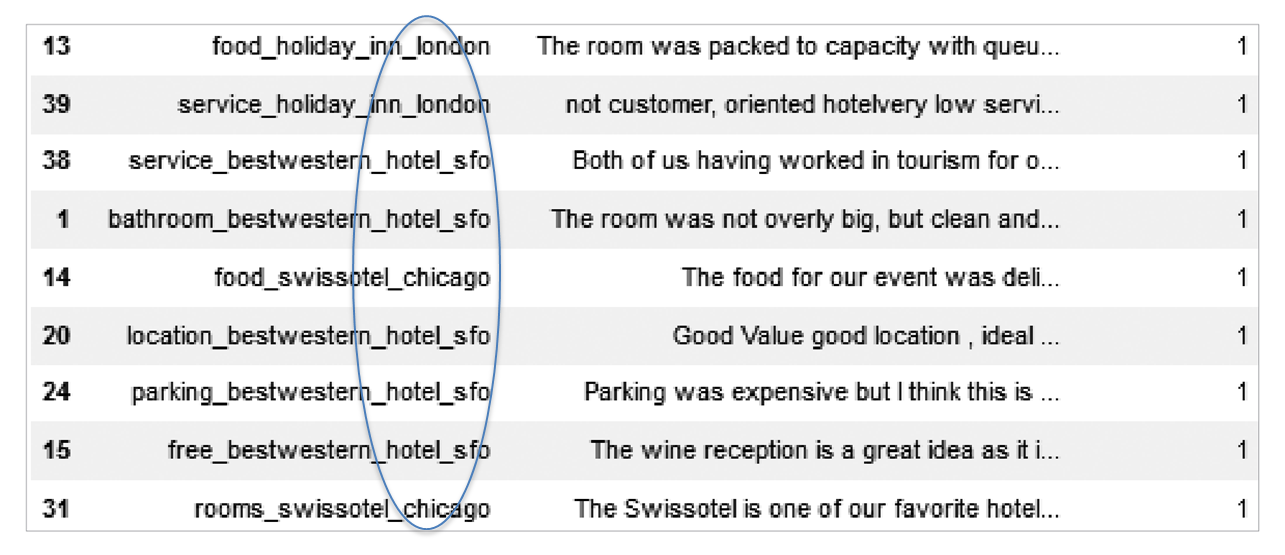
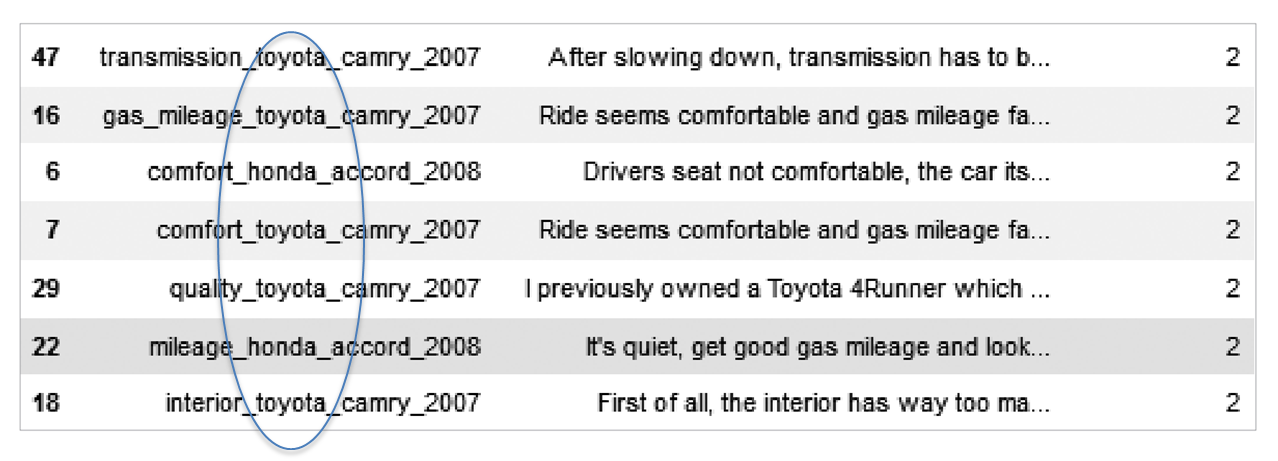
document_df = pd.DataFrame({'filename':filename_list, 'opinion_text':opinion_text})
document_df.head()