오늘 배워 오늘 쓰는 OpenAPI/Quick Start
음성인식 (STT) 빨리 시작하기 - 카카오 OpenAPI
ai-creator
2020. 3. 6. 17:37
반응형

카카오에서는 음성인식(STT, Speech-To-Text)을 무료로 제공하고 있습니다.
ㅁ 1일 무료 허용량
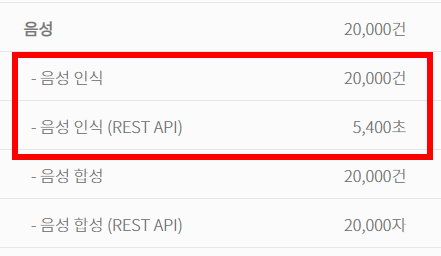
하루에 음성인식은 20,000건 / 5,400초(90분)를 무료로 제공하고 있습니다.
빠르게 살펴보겠습니다.
<< 순서 >>
| Step 1) |
사전준비 - 음성 인식 사용 여부 체크 - rest api key 찾기 |
| Step 2) | 구현 |
Step 1) 사전 준비
1-1) 음성 사용 On
- 내 애플리케이션 > 설정 > 음성 > [ON] 으로 설정 변경

1-2) REST API 키 확인

Step 2) 구현 (Quick Start)
ㅁ 음성 파일 준비

용어정리
- sample rate : 현실 세계의 아날로그 소리를 잘게 쪼갠 비율(속도). 잘게 쪼개진 하나를 샘플이라 부른다.
== 1초당 추출되는 샘플 개수 ex:) 44100 Hz - 1초당 44100개의 샘플
- channel : 스피커 수와 연관 있다.
- bits per sample : 하나의 샘플을 표현하기 위해 사용되는 bit 수.
- bit rate : 1초당 비트 전송 수. (sample rate * channel * bits per sample)
- RAW PCM 포맷 : PCM(Pulse code modulation)로 표현한 오디오 데이터를 압축하지 않은 RAW 형태(wav 등)
오디오 포맷에 관한 자세한 설명은 다른 블로그를 참고하세요.
카카오톡 샘플 오디오 파일 다운로드하기 ("헤이 카카오"라고 녹음 되어 있습니다)
- 해당 형식에 맞춰 오디오 파일을 준비합니다.
ㅁ 소스코드
import requests
import json
kakao_speech_url = "https://kakaoi-newtone-openapi.kakao.com/v1/recognize"
rest_api_key = '<YOUR REST API KEY>'
headers = {
"Content-Type": "application/octet-stream",
"X-DSS-Service": "DICTATION",
"Authorization": "KakaoAK " + rest_api_key,
}
with open('heykakao.wav', 'rb') as fp:
audio = fp.read()
res = requests.post(kakao_speech_url, headers=headers, data=audio)ㅁ 결과
이런 재밌는 결과가 나왔네요~!
print(res.text)
# ------newtonemQRqgAYxWY2ZhLN2
# Content-Type: application/json; charset=UTF-8
#
# {"type":"beginPointDetection","value":"BPD"}
# ------newtonemQRqgAYxWY2ZhLN2
# Content-Type: application/json; charset=UTF-8
#
# {"type":"partialResult","value":"he"}
# ------newtonemQRqgAYxWY2ZhLN2
# Content-Type: application/json; charset=UTF-8
#
# {"type":"partialResult","value":"헤이 카카오"}
# ------newtonemQRqgAYxWY2ZhLN2
# Content-Type: application/json; charset=UTF-8
#
# {"type":"endPointDetection","value":"EPD"}
# ------newtonemQRqgAYxWY2ZhLN2
# Content-Type: application/json; charset=UTF-8
# Speech-Length: 2
#
# {"type":"finalResult","value":"헤이 카카오","nBest":[{"value":"헤이 카카오","score":88},{"value":"헤이 카카오야","score":0}]}
# ------newtonemQRqgAYxWY2ZhLN2--
# beginPointDetection # 사용자가 말하기 시작하는 것으로 판단되었을 때
# partialResult # 사용자가 말을 끝내기 전에 음성의 중간 인식 결과가 나왔을 때로, value에 중간 결과가 담김. 여러 번 발생할 수 있음
# endPointDetection # 사용자가 말하는 것을 끝마친 것으로 판단되었을 때
# finalResult # 사용자가 말한 음성의 최종 인식 결과가 나왔을 때로, value에 최종 인식 결과가 담김
# errorCalled # 음성 인식이 실패 했을 때로, value에 에러 메시지가 담김
(참고) finalResult 를 추출하는 방법
result_json_string = res.text[res.text.index('{"type":"finalResult"'):res.text.rindex('}')+1]
result = json.loads(result_json_string)
print(result)
print(result['value'])저작물의 저작권은 작성자에게 있습니다.
공유는 자유롭게 하시되 댓글 남겨주세요~
상업적 용도로는 무단 사용을 금지합니다.
끝까지 읽어주셔서 감사합니다^^
반응형