
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 인공지능
- Python
- 독학
- 딥러닝
- Ai
- 파이썬게임만들기
- 파이썬게임
- 구글캘린더
- Quickstart
- 구글
- 구글일정
- 소스코드
- Selenium
- 웹크롤링
- kakao
- 카카오
- 파이썬독학
- 기본기
- 파이썬
- 머신러닝
- 빅데이터
- 오늘배워오늘쓰는
- 업무자동화
- 간단한파이썬게임
- 파이썬간단한게임
- 자동화
- STT
- OpenAPI
- 크롤링
- 음성인식
- Today
- Total
ai-creator
[Python/Windows] Selenium 크롤러 - 네이버 자동 로그인 (캡차 해결 버전) 본문
[Python/Windows] Selenium 크롤러 - 네이버 자동 로그인 (캡차 해결 버전)
ai-creator 2020. 3. 10. 12:08
<< 목표 >>
python프로그램을 통해서 네이버 자동 로그인을 수행하고자 합니다.
네이버 로그인의 경우, 다양한 웹사이트에서 연동하여 사용하고 있죠?



그러니, 네이버 자동 로그인 프로그램을 만들어 놓으면, 네이버 계정 연동을 해 놓은 사이트들 모두 사용가능하다는 의미입니다^^
<< 사전 준비 >>
ㅁ 라이브러리 설치
$ pip install selenium
$ pip install pyperclip
ㅁ 크롬 웹 드라이버 설치 다운로드
우리가 개발한 파이썬 크롤링 소프트웨어에서 크롬(chrome)브라우저의 기능을 이용하도록 하기 위해서 웹드라이버(web driver)를 설치해야 합니다.
> windows
1) 크롬 버전을 확인 합니다.

2) 크롬 버전에 맞는 웹드라이버를 다운로드 합니다.
> 다운로드 URL : http://chromedriver.chromium.org/downloads

ㅁ MacOS
** MacOS에서 네이버 로그인 캡차 해결을 위해서는
> https://ai-creator.tistory.com/215로 이동하세요!!!
$ brew cask install chromedriver
정상 설치 되었다면, 다음과 같이 설치경로 + 성공 메시지가 출력됩니다.

<< 구현 순서 >>
| Step 1 | 크롬 웹 드라이버 경로 설정 |
| Step 2 | 크롬 웹 드라이버로 URL 접속 |
| Step 3 | 네이버 로그인 창에 아이디와 비밀번호 입력 |
| Step 4 | 네이버 로그인 버튼 클릭 |
| Step 5 | 네이버 캡차 우회하여 로그인 하기 |
| Step 6 | 브라우저 등록 버튼 클릭 |
Step 1) 크롬 웹 드라이버 경로 설정
> 다운받은 크롬 웹드라이버 경로를 변경하여 사용하세요.
# 자동화 테스트를 위해 셀리니움을 불러옵니다.
from selenium import webdriver
import time
# 크롬 웹 드라이버의 경로를 설정합니다.
# 윈도우의 경우 ex) "C:\chrome_driver\80\chromedriver.exe"
# 맥의 경우는 PATH가 설정되어 있으므로, webdriver.Chrome() 만 선언해도 됩니다.
driver = webdriver.Chrome(<드라이버 경로를 넣어주세요>)Step 2) 크롬 웹 드라이버로 URL 접속
# 접속할 url
url = "https://nid.naver.com/nidlogin.login"
# 접속 시도
driver.get(url)크롬을 통해서 자동 실행되는 화면을 볼 수 있습니다.
Step 3) 네이버 로그인 창에 아이디와 비밀번호 입력
아이디와 비밀번호 정보를 알기 위해서
입력창에서 오른쪽마우스 클릭 > [검사] 를 클릭하면, 오른쪽에 화면이 생깁니다.
Elements란을 클릭하면, id="id", name="id" 라고 되어 있네요.
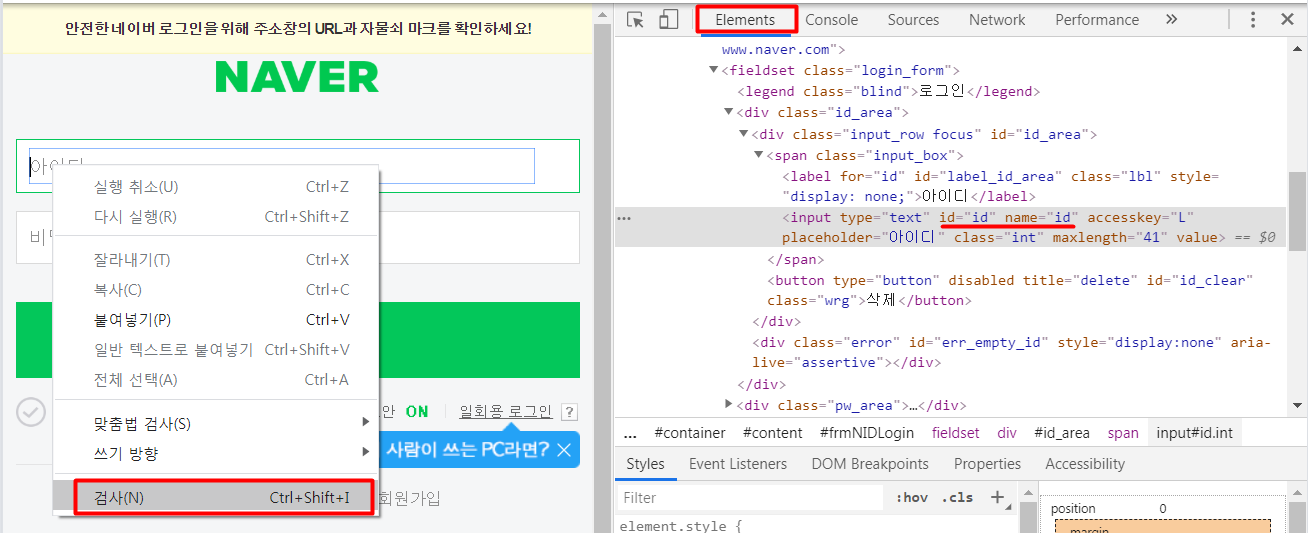
동일한 방법으로 비밀번호란도 확인을 해보면, id="pw", name="pw"라고 되어 있습니다.
테스트하고 싶은 계정의 id와 pw를 dictionary에 담은 후, 해당 값을 보내보겠습니다.
login = {
"id" : "<이곳에 ID를 입력하세요>",
"pw" : "<이곳에 PW를 입력하세요>"
}
# 아이디와 비밀번호를 입력합니다.
time.sleep(0.5) ## 0.5초
# driver.find_element_by_name('id').send_keys('아이디') # "아이디라는 값을 보내준다"
driver.find_element_by_name('id').send_keys(login.get("id"))
time.sleep(0.5) ## 0.5초
driver.find_element_by_name('pw').send_keys(login.get("pw")) 저는 id로 test, pw는 abcd를 보냈는데요. 화면에 이렇게 보이네요^^ 신기합니다!

Step 4) 네이버 로그인 버튼 클릭
동일하게, [로그인]버튼 > 오른쪽 마우스 > 검사 > Elements를 보면, type이 submit 임을 알 수 있습니다.
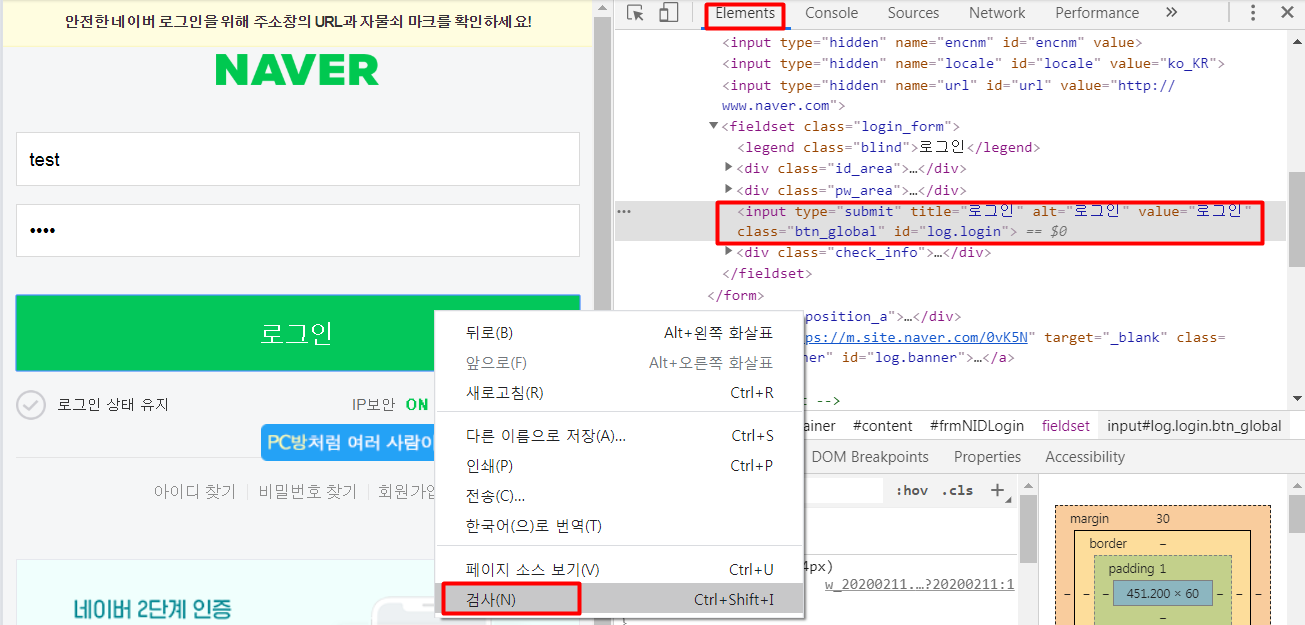
XPath를 복사 합니다.
: 오른쪽 마우스 > Copy > Copy XPath

driver.find_element_by_xpath('//*[@id="log.login"]').click()안타깝게도 사용자 입력이 아닌 소프트웨어적으로 로그인을 시도하는 것이 발각(?) 되어 캡차 입력창이 열렸습니다.

Step 5) 네이버 캡차 우회하여 로그인 하기
> 참고 : https://hyrama.com/?p=693
참고한 내용에 따르면,
Selenium을 이용하고 있는 대부분의 이용자들은 element.send_keys() 메서드를 이용하여 로그인을 시도했습니다. 그러나 Selenium의 driver를 이용하여 아이디 및 비밀번호를 element.send_keys()메서드를 이용하여 로그인 시도 시 비정상적인 접근 방식으로 네이버 Captcha가 탐지하게 됐습니다.
<< 해결방법 : Key 조합>>
Ctrl+V 키 조합을 element에 보낼 경우 네이버 Captcha가 비정상적인 로그인 시도를 탐지하지 못하고 정상적인 로그인에 성공합니다. Clipboard 기능을 이용하여 아이디 및 비밀번호를 복사한 후에 로그인창에 붙여넣기를 하면 쉽게 네이버 Captcha를 뚫을 수 있습니다.
해당 웹사이트에 소스코드도 오픈되어 있습니다. 이 포스팅에서는 소스코드를 조금 수정하여 사용하였습니다.
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import pyperclip
def clipboard_input(user_xpath, user_input):
temp_user_input = pyperclip.paste() # 사용자 클립보드를 따로 저장
pyperclip.copy(user_input)
driver.find_element_by_xpath(user_xpath).click()
ActionChains(driver).key_down(Keys.CONTROL).send_keys('v').key_up(Keys.CONTROL).perform()
pyperclip.copy(temp_user_input) # 사용자 클립보드에 저장 된 내용을 다시 가져 옴
time.sleep(1)=> Ctrl+V 조합으로 키를 추가해서 보내는 코드입니다. 함수로 되어 있으니 id/pw를 입력할 때, 해당함수를 호출 하겠습니다.
웹브라우저는 새로고침을 하여 입력이 없는 상태로 만들고, 아래 코드를 수행합니다.
clipboard_input('//*[@id="id"]', login.get("id"))
clipboard_input('//*[@id="pw"]', login.get("pw"))
driver.find_element_by_xpath('//*[@id="log.login"]').click()로그인이 되었네요!!
Step 6) 브라우저 등록 버튼 클릭
보안을 위해서 로그인등록이 되어 있지 않은 브라우저에서 로그인을 시도하면, 아래와 같은 화면이 나옵니다.
이제 셀리니움을 통해서 [등록] 버튼을 클릭하게 하면 되겠죠?
xpath를 구하는 방법은 step4와 동일합니다. 다시 한번 반복해보시죠~!!
[등록] 버튼 오른쪽 마우스 클릭 > 검사 > Eelements
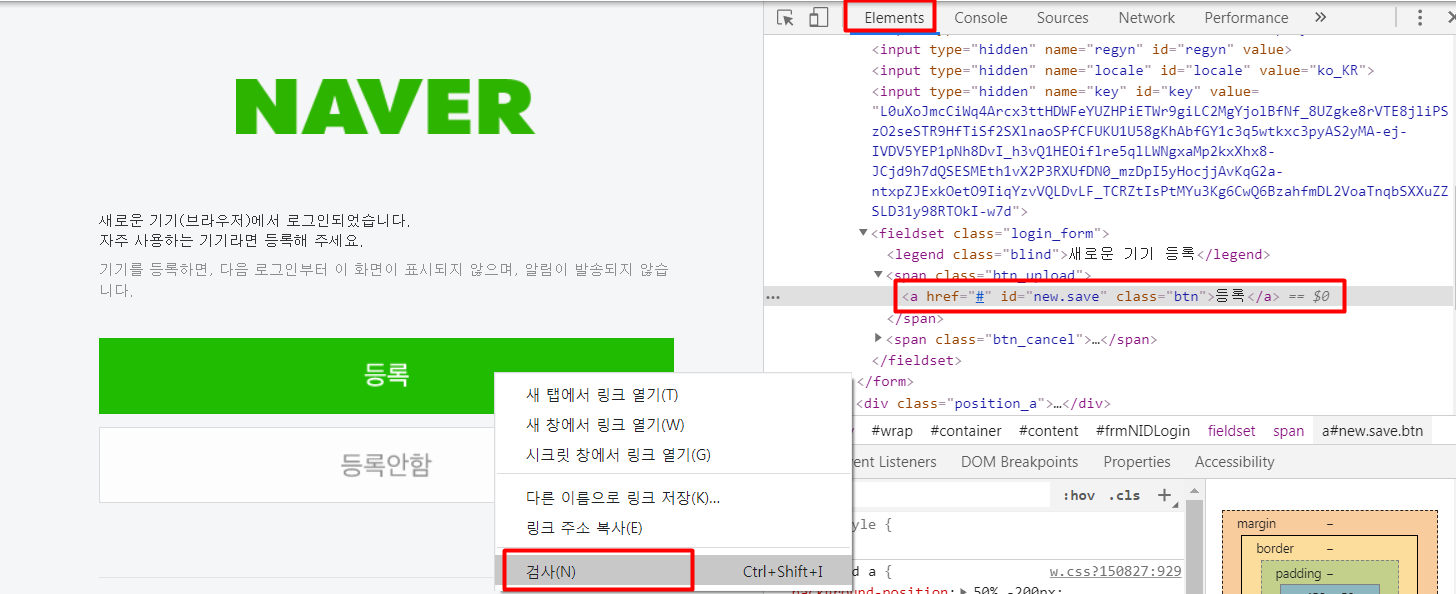
회색bar에서 오른쪽 마우스 클릭 > Copy > Copy XPath
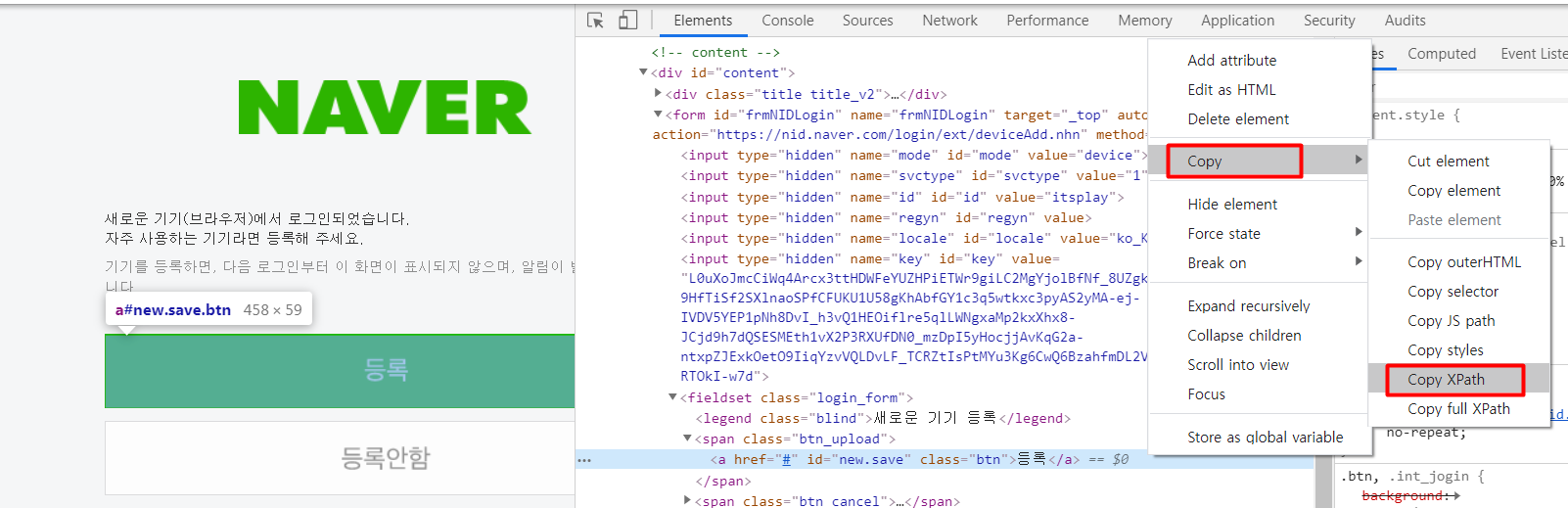
# 브라우저 등록 클릭
driver.find_element_by_xpath('//*[@id="new.save"]').click()로그인 성공~~~~

<< 참고 >>
- 웹크롤링이 필요한 이유 : https://ndb796.tistory.com/120
- 셀리니움을 활용한 네이버 자동 로그인 : https://youtu.be/UenvOvag0B4
- 네이버 로그인시 캡차 우회하는 방법 : https://hyrama.com/?p=693
- Selenium API 문서 : https://selenium-python.readthedocs.io/index.html
저작물의 저작권은 작성자에게 있습니다.
공유는 자유롭게 하시되 댓글 남겨주세요~
상업적 용도로는 무단 사용을 금지합니다.
끝까지 읽어주셔서 감사합니다^^
'오늘 배워 오늘 쓰는 OpenAPI > Quick Start' 카테고리의 다른 글
| [Python/MacOS] Selenium 크롤러 - 네이버 자동 로그인 (캡차 해결 버전) (5) | 2020.05.21 |
|---|---|
| 유투브 영상으로 Google Speech-to-Text 기능과 성능 확인 (0) | 2020.03.28 |
| [Python] 아파트 매매 실거래가 수집하기 (feat. 국토교통부 OpenAPI) (14) | 2020.03.09 |
| Python으로 네이버 블로그 자동 포스팅 하기 (5) | 2020.03.06 |
| 음성인식 (STT) 빨리 시작하기 - 카카오 OpenAPI (6) | 2020.03.06 |



