
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Python
- 구글
- 파이썬
- 인공지능
- 구글캘린더
- 파이썬게임만들기
- 파이썬독학
- 크롤링
- 오늘배워오늘쓰는
- 업무자동화
- 카카오
- 자동화
- kakao
- 파이썬게임
- Ai
- OpenAPI
- 기본기
- 웹크롤링
- Selenium
- 머신러닝
- 독학
- 딥러닝
- Quickstart
- 음성인식
- 파이썬간단한게임
- 빅데이터
- 소스코드
- 간단한파이썬게임
- STT
- 구글일정
- Today
- Total
ai-creator
[머신러닝 기초] 텍스트분석 - classification (20newsgroups 데이터) 본문
[머신러닝 기초] 텍스트분석 - classification (20newsgroups 데이터)
ai-creator 2021. 11. 27. 10:27ㅁ 텍스트 분석 주요 영역
1) 텍스트 분류
2) 감정 분석
3) 텍스트 요약
4) 텍스트 군집화와 유사도 측정
ㅁ 텍스트분석 머신러닝 수행 프로세스
"text문서 -> 가공(전처리) -> feature -> ml학습 -> 예측 -> 평가" 과정은 다른 ML 프로세스와 동일
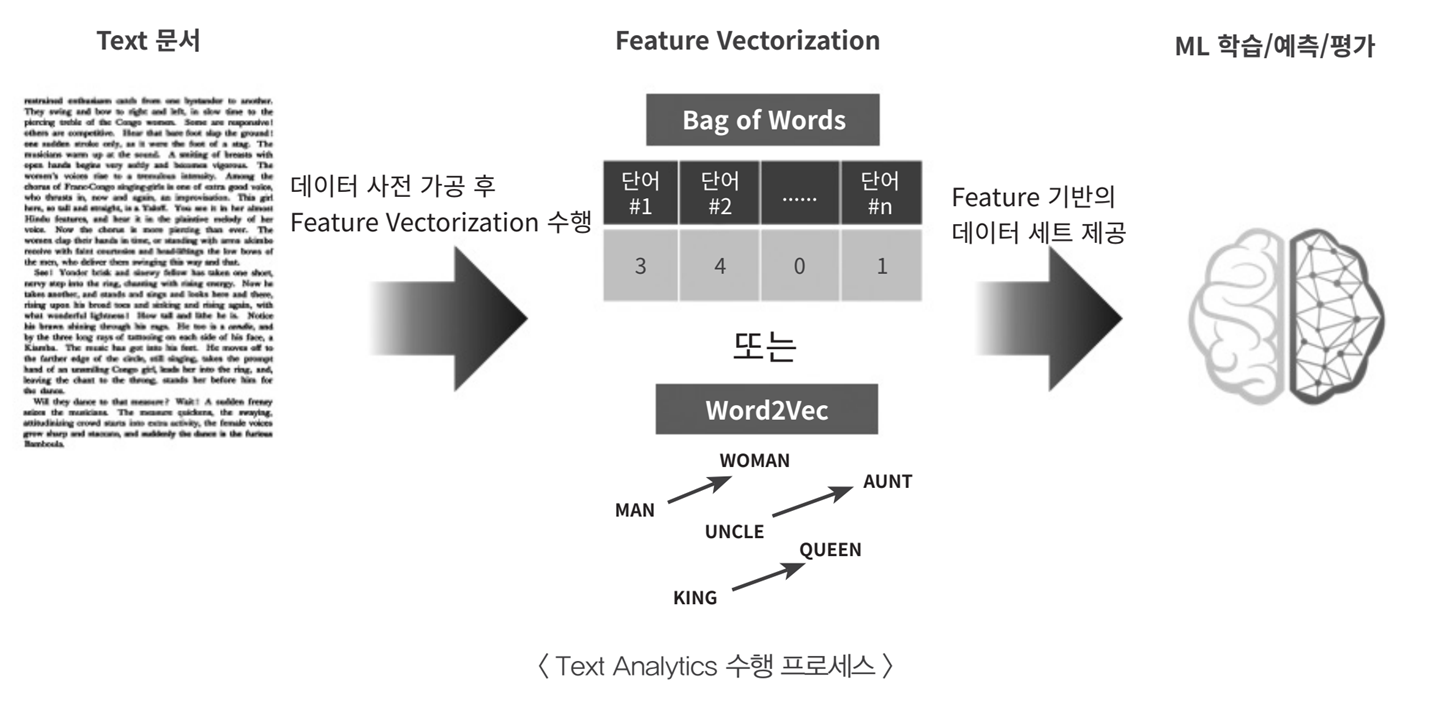
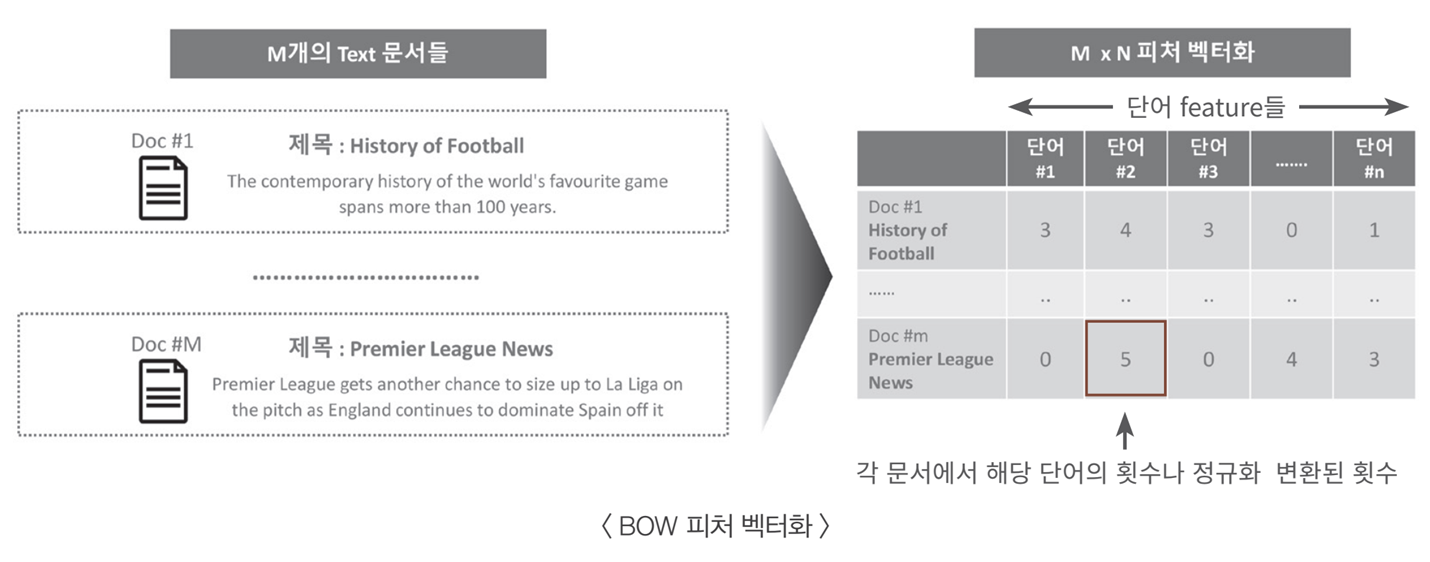
가공(전처리)
1) 클린징(cleansing) : 텍스트 분석에 방해가 되는 불필요한 문자, 기호등을 제거 (ex. HTML, XML 태그)
2) 토큰화(tokeniation) : 문장 토큰화, 단어 토큰화, n-gram
3) 필터링, 스톱워드 제거, 철자 수정 : 분석에 큰 의미가 없는 단어(ex. a, the, is, will), 잘못된 철자 수정
4) stemming / lemmatization : 어근(단어 원형) 추출 (비교급, 과거형 ex. happier, plays)
등
Feature
단어의 순서가 중요하지 않은 경우, 문맥이나 순서를 무시하고 피처값을 추출
- Count기반
- TF-IDF (단어 빈도-역 문서 빈도, Term Frequency-Inverse Document Frequency)기반
Feature는 ML알고리즘 특성에 맞게 생성한다.
등
참고) TF-IDF(Term Frequency-Inverse Document Frequency) 알고리즘
: 개별문서에서 자주 나타나는 단어에 높은 가중치를 주되, 모든 문서에서 전반적으로 자주 나타나는 단어에 대해서는 패널티를 주는 방식
ex) 주식과 관련된 주제의 문서인 경우 주가, 종가, 시가등의 단어는 중요하지 않을 수 있음
- TF : Term Frequency
- DF : Document Frequency (DF가 클수록 다수 문서에 쓰이는 범용적인 단어)
- IDF : Inverse Document Frequency

ex) Doc1 문서에서의 TF-IDF값
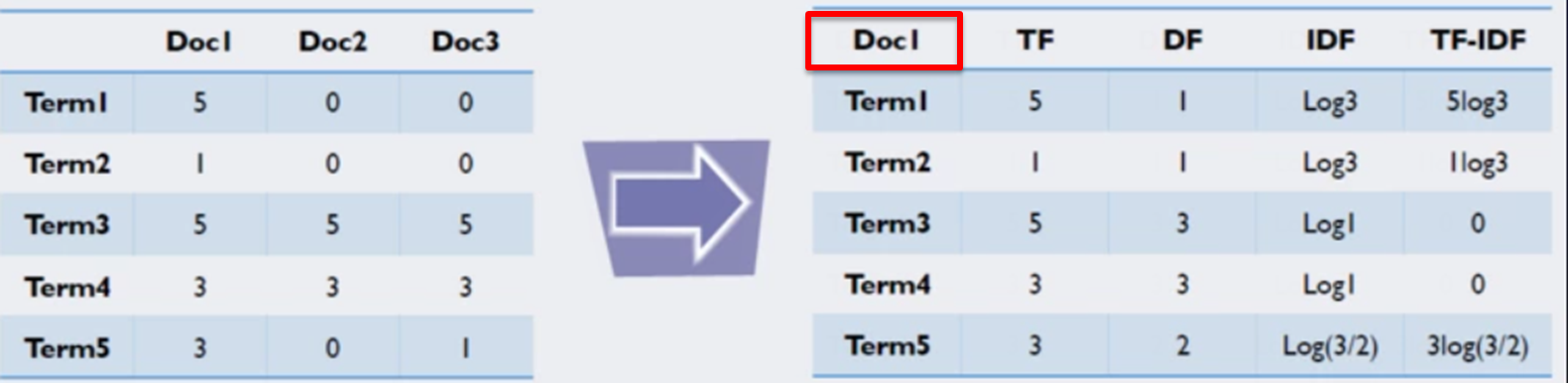
위 표를 기준으로 할때 doc1을 가려내는 데 가장 중요한 역할을 하는 단어는 무엇일까요? 그 후보는 term1과 term2가 될 겁니다. 둘 모두 doc1에만 쓰였기 때문입니다. 그런데 이 중에서도 term1이 term2보다 많이 쓰였기 때문에 term1이 가장 중요한 단어가 될 겁니다. doc1의 term1에 대응하는 TF-IDF가 가장 높음을 역시 확인할 수 있습니다. 그렇다면 반대로 모든 문서에 비슷하게 많이 쓰인 term3, term4는 어떨까요? 이들에 대응하는 TF-IDF 값은 0입니다. 바꿔 말하면 term3과 term4는 모두 doc1이라는 문서를 특징짓는 데 아무런 정보를 가지고 있지 않다는 이야기입니다.
Sklearn API
※ vector의 get_feature_names_out() 메소드가 없다면, 버전업데이트가 필요하다.
$ pip install -U --user scikit-learn==1.0.1이를 위해 sklearn에서는 API를 지원한다.
| 목적 | import | API |
| text featuring |
from sklearn.feature_extraction.text import CountVectorizer | CountVectorizer() |
| from sklearn.feature_extraction.text import TfidfVectorizer | TfidfVectorizer() | |
| stop_words="english" 인 경우 제외되는 단어 목록 |
import sklearn | sklearn.feature_extraction.text.ENGLISH_STOP_WORDS |

stop_words의 경우는 custom하게 만들 수도 있다. stop_words=['the','an','a'] 같이 파라메터를 전달하면, 해당 단어만 제외하고 추출한다.

코드에서 보면,
** 반드시 "학습"데이터를 이용해 fit()이 수행된 CountVectorizer객체를 이용해 "테스트"데이터를 변환(transform)해야 한다는 것! 그래야만 학습시 설정된 CountVectorizer의 피처 개수와 테스트 데이터를 CountVectorizer로 변환할 피처개수가 같아진다.
CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
## 결과 출력
print(vectorizer.get_feature_names_out())
pd.DataFrame(X.toarray(), columns=list(vectorizer.get_feature_names_out()))결과

CountVectorizer : stopwords를 사용한 경우
## sklearn.feature_extraction.text.ENGLISH_STOP_WORDS 의 단어 목록이 제외된다.
vectorizer = CountVectorizer(stop_words="english")
X = vectorizer.fit_transform(corpus)
## 결과 출력
print(vectorizer.get_feature_names_out())
pd.DataFrame(X.toarray(), columns=list(vectorizer.get_feature_names_out()))
결과

TfidfVectorizer
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
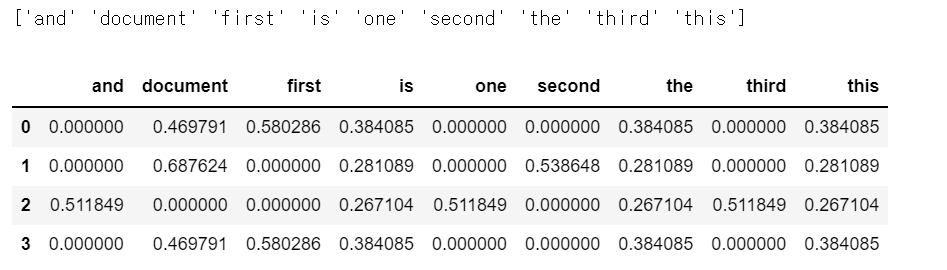
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)
## 출력
print(vectorizer.get_feature_names_out())
pd.DataFrame(X.toarray(), columns=list(vectorizer.get_feature_names_out()))결과
TfidfVectorizer - stopwords를 사용한 경우
## sklearn.feature_extraction.text.ENGLISH_STOP_WORDS 의 단어 목록이 제외된다.
vectorizer = TfidfVectorizer(stop_words="english")
X = vectorizer.fit_transform(corpus)
## 결과 출력
print(vectorizer.get_feature_names_out())
pd.DataFrame(X.toarray(), columns=list(vectorizer.get_feature_names_out()))
참고) n-gram
문장을 단어별로 하나씩 토큰화 할 경우 문맥적인 의미는 무시 될 수 밖에 없다. 이러한 문제를 조금이라도 해결해 보고자 도입된 것이 n-gram이다. n-gram은 연속된 n개의 단어를 하나의 토큰화 단위로 분리해 내는 것이다.
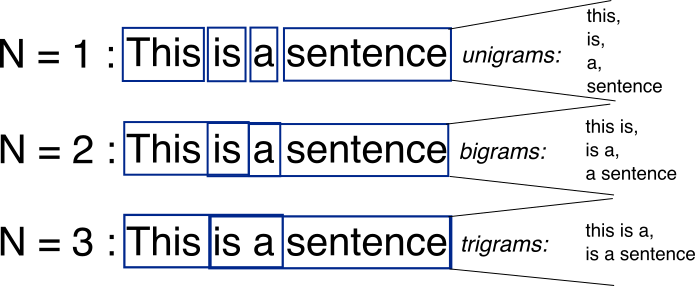
CountVectorizer : n-gram을 사용한 경우
- ngram_range = (min, max)
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer2 = CountVectorizer(analyzer='word', ngram_range=(2, 2))
X2 = vectorizer2.fit_transform(corpus)
vectorizer2.get_feature_names_out()
## 결과 출력
print(vectorizer2.get_feature_names_out())
pd.DataFrame(X2.toarray(), columns=list(vectorizer2.get_feature_names_out()))결과

ngram_range=(1, 3) 이라면?
['and' 'and this' 'and this is' 'document' 'document is' 'document is the'
'first' 'first document' 'is' 'is the' 'is the first' 'is the second'
'is the third' 'is this' 'is this the' 'one' 'second' 'second document'
'the' 'the first' 'the first document' 'the second' 'the second document'
'the third' 'the third one' 'third' 'third one' 'this' 'this document'
'this document is' 'this is' 'this is the' 'this the' 'this the first']0) 데이터 설명 : 20뉴스그룹

- 참고 : sklearn api (20 뉴스그룹 분류 , Link)
총 20가지의 주제를 가진 뉴스데이터
## pprint(list(newsgroups_train.target_names))
'alt.atheism',
'comp.graphics',
'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware',
'comp.windows.x',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian',
'talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc'
| 목적 | import | API |
| 데이터 로드 | from sklearn.datasets import fetch_20newsgroups | fetch_20newsgroups(subset='all') fetch_20newsgroups(subset='train') fetch_20newsgroups(subset='test') |
| 파라메터 - subset : 훈련(train)과 테스트(test)를 설정 - remove : 삭제하고 싶은 것을 tuple 형태로 설정 ('headers', 'footers', 'quotes'), telling it to remove headers, signature blocks, and quotation blocks respectively - categories : 분류하고자 하는 카테고리를 대입. 여기에서는 위에서 categories 로 정의한 변수를 대입합니다. |
ㅁ 텍스트 분류
- 실습 : 텍스트 분류 실습 (20 뉴스그룹 분류, Link)
텍스트 분류 수행 프로세스도 이전에 학습한 분류 프로세스와 동일하다고 설명했다.
즉, "text문서 -> 가공(전처리) -> feature -> ml학습 -> 예측 -> 평가" 과정은 다른 ML 프로세스와 동일하다.
input데이터가 text로 변경된것 이외는 달라진게 없다는 사실을 잘 염두해 둬야 한다.
그러므로, 학습용 데이터를 만들어야 한다.
feature 와 target으로 이루어져 있는 학습데이터이며,
이번실습데이터로는 feature는 단어가 되고, target은 문서에 해당하는 주제가 된다.
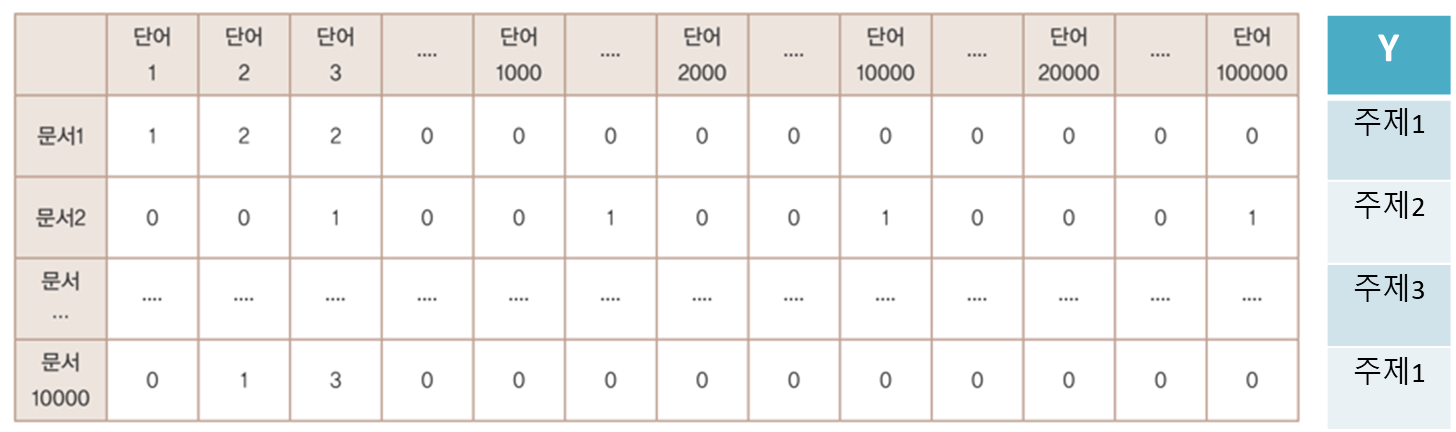
위에서 언급한 내용을 다시 한번 상기해보자.
가공(전처리)
1) 클린징(cleansing) : 텍스트 분석에 방해가 되는 불필요한 문자, 기호등을 제거 (ex. HTML, XML 태그)
2) 토큰화(tokeniation) : 문장 토큰화, 단어 토큰화, n-gram
3) 필터링, 스톱워드 제거, 철자 수정 : 분석에 큰 의미가 없는 단어(ex. a, the, is, will), 잘못된 철자 수정
4) stemming / lemmatization : 어근(단어 원형) 추출 (비교급, 과거형 ex. happier, plays)
등
Feature
단어의 순서가 중요하지 않은 경우, 문맥이나 순서를 무시하고 피처값을 추출
- Count기반
- TF-IDF (단어 빈도-역 문서 빈도, Term Frequency-Inverse Document Frequency)기반
Feature는 ML알고리즘 특성에 맞게 생성한다.
등
1-1) 데이터 준비 및 전처리
- 학습, 테스트 용 데이터를 각각 준비한다.
from sklearn.datasets import fetch_20newsgroups
##################
# 학습용 데이터
##################
# subset='train'으로 학습용(Train) 데이터만 추출, remove=('headers', 'footers', 'quotes')로 내용만 추출
train_news= fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'), random_state=156)
X_train = train_news.data
y_train = train_news.target
print(type(X_train))
##################
# 테스트용 데이터
##################
# subset='test'으로 테스트(Test) 데이터만 추출, remove=('headers', 'footers', 'quotes')로 내용만 추출
test_news= fetch_20newsgroups(subset='test',remove=('headers', 'footers','quotes'),random_state=156)
X_test = test_news.data
y_test = test_news.target
print('학습 데이터 크기 {0} , 테스트 데이터 크기 {1}'.format(len(train_news.data) , len(test_news.data)))결과
<class 'list'>
학습 데이터 크기 11314 , 테스트 데이터 크기 75321-2) Featuring
- 학습, 테스트 용 데이터를 각각 준비한다.
- 학습용으로 생성된 counter vector의 object를 테스트용에 적용해야 한다.
from sklearn.feature_extraction.text import CountVectorizer
# Count Vectorization으로 feature extraction 변환 수행.
cnt_vect = CountVectorizer()
cnt_vect.fit(X_train)
##################
# 학습용 데이터
##################
X_train_cnt_vect = cnt_vect.transform(X_train)
print('학습 데이터 Text의 CountVectorizer Shape:',X_train_cnt_vect.shape) ## 11314x101631 => 11314개 문서, 101631개의 단어
##################
# 테스트용 데이터
##################
# 학습 데이터로 fit( )된 CountVectorizer를 이용하여 테스트 데이터를 feature extraction 변환 수행.
X_test_cnt_vect = cnt_vect.transform(X_test)
print('테스트 데이터 Text의 CountVectorizer Shape:',X_test_cnt_vect.shape)결과
학습 데이터 Text의 CountVectorizer Shape: (11314, 101631)
테스트 데이터 Text의 CountVectorizer Shape: (7532, 101631)
1-3) ML학습
- 데이터 준비가 되었다면, 분류에 적합한 모델을 선택하여 학습을 진행한다
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# LogisticRegression을 이용하여 학습/예측/평가 수행.
lr_clf = LogisticRegression()
lr_clf.fit(X_train_cnt_vect , y_train)
1-4) 모델 예측 및 평가
pred = lr_clf.predict(X_test_cnt_vect)
print('CountVectorized Logistic Regression 의 예측 정확도는 {0:.3f}'.format(accuracy_score(y_test,pred)))결과
CountVectorized Logistic Regression 의 예측 정확도는 0.605
예측결과가 마음에 들지 않는다면,
- 모델의 하이퍼파라메터 튜닝
- 다른 모델 선택 및 비교
- 데이터 전처리
등의 작업을 하여, 1-1~1-4)를 반복수행 하면 된다.
ㅁ Reference
- [책] 파이썬 머신러닝 완벽가이드
- [블로그] 파이썬 머신러닝 완벽가이드 정리본 (Link)
- [책] 혼자 공부하는 머신러닝+딥러닝
- [소스코드 출처] : https://github.com/wikibook/pymldg-rev
- [블로그] 감서분석과 문서분류 (Link)
'데이터 분석 > 왕초보를 위한 머신러닝' 카테고리의 다른 글
| 하이퍼파라메터 튜닝, Automl로 자동화 하자! (w/pycaret) (0) | 2021.11.27 |
|---|---|
| [머신러닝 기초] 텍스트분석 - Clustering (Opinion Review 데이터) (0) | 2021.11.27 |
| [머신러닝 기초] 비지도학습(Unsupervised-learning) - 군집화(Clustering) (4) | 2021.10.19 |
| [머신러닝 기초] 지도학습 - classification (Logistic Regression) (0) | 2021.10.19 |
| [머신러닝 기초] 지도학습 - 선형 회귀(Regression) 분석 (0) | 2021.10.19 |



