
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- kakao
- 간단한파이썬게임
- 빅데이터
- 파이썬독학
- Selenium
- 구글캘린더
- 소스코드
- 파이썬
- 오늘배워오늘쓰는
- 독학
- Ai
- 자동화
- 인공지능
- STT
- 파이썬게임만들기
- 파이썬간단한게임
- 기본기
- OpenAPI
- 크롤링
- 머신러닝
- 딥러닝
- 카카오
- 구글일정
- 웹크롤링
- Quickstart
- 구글
- Python
- 음성인식
- 업무자동화
- 파이썬게임
Archives
- Today
- Total
ai-creator
[머신러닝 기초] 텍스트분석 - Clustering (Opinion Review 데이터) 본문
데이터 분석/왕초보를 위한 머신러닝
[머신러닝 기초] 텍스트분석 - Clustering (Opinion Review 데이터)
ai-creator 2021. 11. 27. 10:28반응형
1. 텍스트 분석 - Clustering
앞에서 배운 분류와 마찬가지로, input 데이터의 최초 형태만 다른 것이지 input feature로 만들면 동일하게 clustering 알고리즘을 적용하여 분석할 수 있다.
2. 군집화 실습 (Opinion Review)
실습 : 문집 군집화 실습
- 소스 코드 : (Link)
- 데이터셋 : (Link)
2.1) 데이터 설명
- 51개의 텍스트 파일로 구성
- 각 파일은 Tripadvisor(호텔), Edmunds.com(자동차), Amazon.com(전자제품) 사이트에서 가져온 리뷰 문서

- 문서유형을 크게 보면, 전자제품 / 자동차 / 호텔로 되어 있음
- 전자제품은 네비게이션 / 에어팟 / 킨들 / 랩탑 컴퓨터 등

- Amazon.com에서 Garmin nuvi라는 차량용 네비게이션 모델에 대한 리뷰
2.2) 소스코드
2.2.1) 파일읽기
- 지정된 경로의 .data 파일을 모두 읽음
- filename과 opinion_text를 컬럼으로하는 dataframe을 생성함
import pandas as pd
import glob ,os
# 아래는 제 컴퓨터에서 압축 파일을 풀어 놓은 디렉토리이니, 여러분의 디렉토리를 설정해 주십시요
path = './OpinosisDataset1.0/OpinosisDataset1.0/topics'
# path로 지정한 디렉토리 밑에 있는 모든 .data 파일들의 파일명을 리스트로 취합
all_files = glob.glob(os.path.join(path, "*.data"))
filename_list = []
opinion_text = []
# 개별 파일들의 파일명은 filename_list 리스트로 취합,
# 개별 파일들의 파일내용은 DataFrame로딩 후 다시 string으로 변환하여 opinion_text 리스트로 취합
for file_ in all_files:
# 개별 파일을 읽어서 DataFrame으로 생성
df = pd.read_table(file_,index_col=None, header=0,encoding='latin1')
# 절대경로로 주어진 file 명을 가공. 만일 Linux에서 수행시에는 아래 \\를 / 변경. 맨 마지막 .data 확장자도 제거
filename_ = file_.split('\\')[-1]
filename = filename_.split('.')[0]
#파일명 리스트와 파일내용 리스트에 파일명과 파일 내용을 추가.
filename_list.append(filename)
opinion_text.append(df.to_string())
# 파일명 리스트와 파일내용 리스트를 DataFrame으로 생성
document_df = pd.DataFrame({'filename':filename_list, 'opinion_text':opinion_text})
document_df.head()결과

2.2.2) 전처리
- TF-IDF로 피처 벡터화
from nltk.stem import WordNetLemmatizer
import nltk
import string
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
lemmar = WordNetLemmatizer()
def LemTokens(tokens):
return [lemmar.lemmatize(token) for token in tokens]
def LemNormalize(text):
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))
#################
## 벡터화
#################
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vect = TfidfVectorizer(tokenizer=LemNormalize, stop_words='english' , \
ngram_range=(1,2), min_df=0.05, max_df=0.85 )
#opinion_text 컬럼값으로 feature vectorization 수행
feature_vect = tfidf_vect.fit_transform(document_df['opinion_text'])
2.2.3) 군집화 수행 (k=3)
from sklearn.cluster import KMeans
# 3개의 집합으로 군집화
km_cluster = KMeans(n_clusters=3, max_iter=10000, random_state=0)
km_cluster.fit(feature_vect)
cluster_label = km_cluster.labels_
# 소속 클러스터를 cluster_label 컬럼으로 할당하고 cluster_label 값으로 정렬
document_df['cluster_label'] = cluster_label
document_df.sort_values(by='cluster_label')결과
Cluster #0 : _______________
더보기

포터블 전자기기
Cluster #1 : _______________
더보기

호텔리뷰
Cluster #2 : _______________
더보기
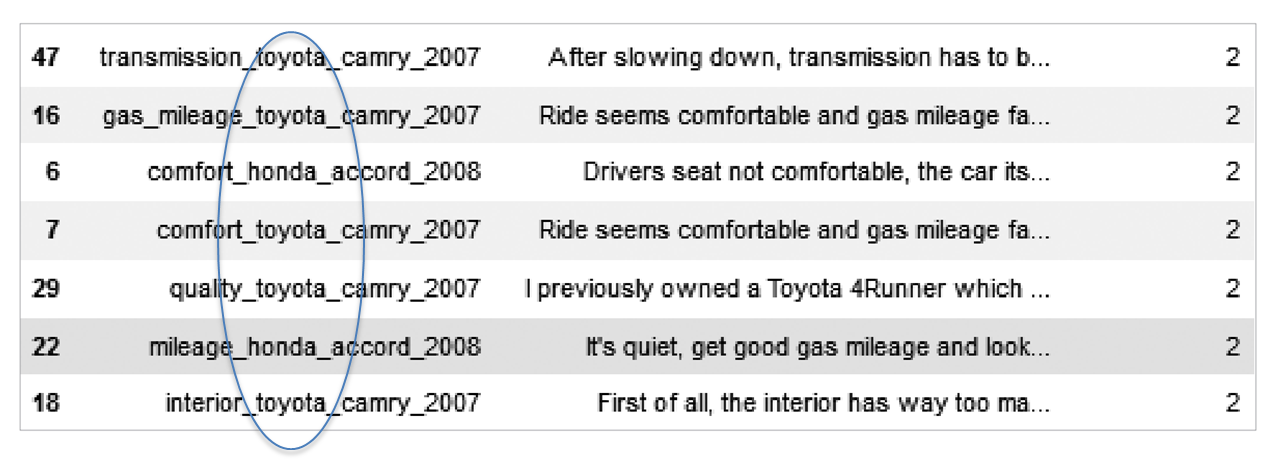
자동차 리뷰
ㅁ Reference
- [책] 파이썬 머신러닝 완벽가이드
- [블로그] 파이썬 머신러닝 완벽가이드 정리본 (Link)
- [소스코드 출처] : https://github.com/wikibook/pymldg-rev
반응형
'데이터 분석 > 왕초보를 위한 머신러닝' 카테고리의 다른 글
| 하이퍼파라메터 튜닝, Automl로 자동화 하자! (w/pycaret) (0) | 2021.11.27 |
|---|---|
| [머신러닝 기초] 텍스트분석 - classification (20newsgroups 데이터) (0) | 2021.11.27 |
| [머신러닝 기초] 비지도학습(Unsupervised-learning) - 군집화(Clustering) (4) | 2021.10.19 |
| [머신러닝 기초] 지도학습 - classification (Logistic Regression) (0) | 2021.10.19 |
| [머신러닝 기초] 지도학습 - 선형 회귀(Regression) 분석 (0) | 2021.10.19 |
'데이터 분석/왕초보를 위한 머신러닝' Related Articles
more




Comments