
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 구글캘린더
- 딥러닝
- Selenium
- kakao
- 업무자동화
- 구글일정
- STT
- 오늘배워오늘쓰는
- 파이썬
- 독학
- 인공지능
- 크롤링
- OpenAPI
- 음성인식
- 구글
- 파이썬게임만들기
- Python
- 기본기
- 파이썬간단한게임
- 소스코드
- 파이썬독학
- Quickstart
- Ai
- 자동화
- 웹크롤링
- 빅데이터
- 카카오
- 파이썬게임
- 머신러닝
- 간단한파이썬게임
- Today
- Total
ai-creator
OpenAPI 활용 - 나만의 인공지능 비서 "자비스" 만들기 (음성제어기) 본문
오.오.쓰 에 오신 것을 환영합니다.
[인공지능 비서, Jarvis 프로젝트 ] 입니다.
아래와 같은 순서로 배워보겠습니다.
ㅁ 꿀팁!
1. 학습 목표
이번 장에서는 이제까지 만든 프로젝트를 연동해보겠습니다.
혹시. 영화 '아이언맨'의 '자비스'를 알고 계시나요? 자비스는 아이언맨이 말로 요청을 하면, 그 요구사항을 이해하고 동작합니다.
마크 저커버그가 몇 시간 만에 자비스를 만들어서 화제가 되기도 했지요.
요즘은 인공지능 스피커가 상용화되었죠.
이제 음성이 기계와 인간 사이의 인터페이스를 하는 세상이 되었습니다.
인공지능 스피커도 있고, 마크 저커버그도 몇 시간 만에 인공지능 비서를 만들었는데 우리는 불가능할까요? 가능합니다!
이번 장에서는 이제까지 만든 OpenAPI 프로젝트를 음성으로 인식하여 동작하게 만드는 프로젝트, 일명 '인공지능 비서, Jarvis 프로젝트'를 진행해 보겠습니다.
[구현 순서]
Jarvis 프로젝트를 위한 구현 순서는 아래와 같습니다.
음성을 통해 제어하기 위해 컴퓨터에 내장된 마이크(mic)로 음성을 수집합니다. 카카오의 Speech-To-Text(이하 STT) OpenAPI로 수집된 음성을 Text로 변환합니다. Text를 분석하여 "날씨"라는 글자가 있다면, "날씨 정보를 이용한 맛집 추천 프로젝트"가 수행되고, "주식"이라는 글자가 있다면, "주식 분석 보고서 자동화 프로젝트"가 수행됩니다.

[최종 결과]

[언어 & 환경(IDE)]
Python 3.7 & Jupter notebook
[프로젝트 리소스 및 소스 코드]
- res/jarvis : 동작 확인을 위한 리스소 파일이 위치한 폴더
- kakao_utils.py : 카카오 메시지 전송을 위한 유틸리티 구현 코드 (참고 : 나에게 카카오톡 보내기)
- food_recommender.ipynb : 날씨 정보를 이용한 맛집 추천 프로젝트(Link)의 구현 코드
- food_recommender_jarvis.py : '날씨 정보를 이용한 맛집 추천 프로젝트'의 구현 코드를 목적에 맞게 수정한 소스 코드 (4. 구현 S수행시 생성 됨)
- stock_report.ipynb : 주식 분석 보고서 자동화 프로젝트(Link)의 구현 코드
- stock_report_jarvis.py : '주식 분석 보고서 자동화 프로젝트'의 구현 코드를 목적에 맞게 수정한 소스코드 (4. 구현 수행시 생성 됨)
- jarvis.ipynb : 구현된 소스 코드
- res/kakao_message/kakao_token.json : 카카오 access token과 refresh token이 관리되는 파일 (참고 : 나에게 카카오톡 보내기)
> 접속 URL : drive.google.com/drive/folders/10KXyPrJ_KEesvAvjnMpx1DS_md7gaN6H?usp=sharing
ai-creator 공유폴더 - Google 드라이브
drive.google.com
※ 프로젝트에 필요한 리소스 및 소스코드의 경로 구성은 자유롭게 설정하면 됩니다. 그러나, 아래 설명되어 있는 코드 구현이 제시된 구성으로 되어 있으니, 동일하게 경로와 파일명으로 구성해 둔다면 별다른 코드 수정 없이 실행해 볼 수 있습니다.
2. 사전 준비
Jarvis 프로젝트를 위해서 네 가지 사전 준비가 필요합니다.
1) 마이크(mic) 준비하기
노트북을 사용하고 있다면, 대부분 내장 마이크가 있습니다. 그런데, 데스크톱을 이용한다면, 내장 마이크가 없는 경우가 있으니 외장 마이크를 준비하셔야 합니다. 만약, 줌(zoom)과 같은 화상 프로그램을 한 번이라도 사용하셨다면, 그때와 동일하게 준비하면 됩니다.

2) 날씨 정보를 이용한 맛집 추천 프로젝트 (Link)
Jarvis 프로젝트는 음성 중에 "날씨"라는 단어가 있으면 "날씨 정보를 이용한 맛집 추천 프로젝트"를 수행합니다. 그러므로, 해당 프로젝트의 내용을 이해하고, 소스코드가 준비되어 있어야 합니다. 전체 프로젝트를 모두 실행하고 이해할 필요는 없만, 꼭 잊지 말고 수정해 두어야 할 부분은 "4. 구현"에 공공데이터 포털의 service_key, 네이버의 client_id와 secret, 카카오의 app_key 값들을 세팅해야 합니다.
3) 주식 분석 보고서 자동화 프로젝트 (Link)
Jarvis 프로젝트는 음성 중에 "주식"이라는 단어가 있으면 "주식 분석 보고서 자동화 프로젝트"를 수행합니다. 그러므로, 해당 프로젝트의 내용을 이해하고, 소스코드가 준비되어 있어야 합니다. 전체 프로젝트를 모두 실행하고 이해할 필요는 없만, 꼭 잊지 말고 수정해 두어야 할 부분은 "4. 구현"에 공공데이터 포털의 service_key, 네이버의 client_id와 secret, 카카오의 app_key 값들을 세팅해야 합니다.
4) 라이브러리 설치
SpeechRecognition 라이브러리는 마이크(mic)로 음성을 수집용으로 사용합니다.
> 참고 URL : pypi.org/project/SpeechRecognition/
$ pip install SpeechRecognition참고 URL의 내용을 보면, source code가 공개되어 있어 사용법이 코드 레벨로 설명이 되어 있고, PyAudio 라이브러리가 필요하다는 내용도 있습니다. 그래서 PyAudio라이브러리를 설치해야 하는데요, pip로 설치할 경우 에러가 잘 발생하는 라이브러리이므로 다음과 같이 .whl 파일을 직접 설치하겠습니다.
Windows를 사용하신다면, 아래에 접속하여 자신의 사양에 맞는 .whl파일을 다운로드합니다.
> 접속 URL : www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio
PyAudio에 해당하는 라이브러리 목록을 보면
PyAudio-{PyAudio버전}-{cp파이썬버전}-{cp파이썬버전}-{윈도 시스템종류}.whl
의 형태로 관리됩니다.

그럼 파이썬 버전과 윈도우시스템 종류 알아야 하는데요,
python버전은 cmd창을 열어 다음 명령어를 수행합니다.
cmd창을 여는 방법은 윈도키 옆 검색창에 "cmd"를 입력하고 엔터를 치면 cmd창이 열립니다.

cmd창에 다음 명령어를 입력해서 결과를 확인합니다.
$ python --version

수행 결과로 보니, 파이썬 3.7 버전 사용 중에 있습니다.
다음은 윈도시스템 종류입니다. 대부분 windows10 이상을 사용 중일텐데요, 본문은 windows10을 기준으로 작성되었습니다. 윈도우 키 옆에 검색창이 하나 있죠? 그 검색 창에 "PC 정보"를 입력합니다.
그리고, 검색된 결과를 클릭합니다. 시스템 종류에 64로 되어 있죠. 그럼 64라고 쓰인 whl파일을 다운로드하면 됩니다.
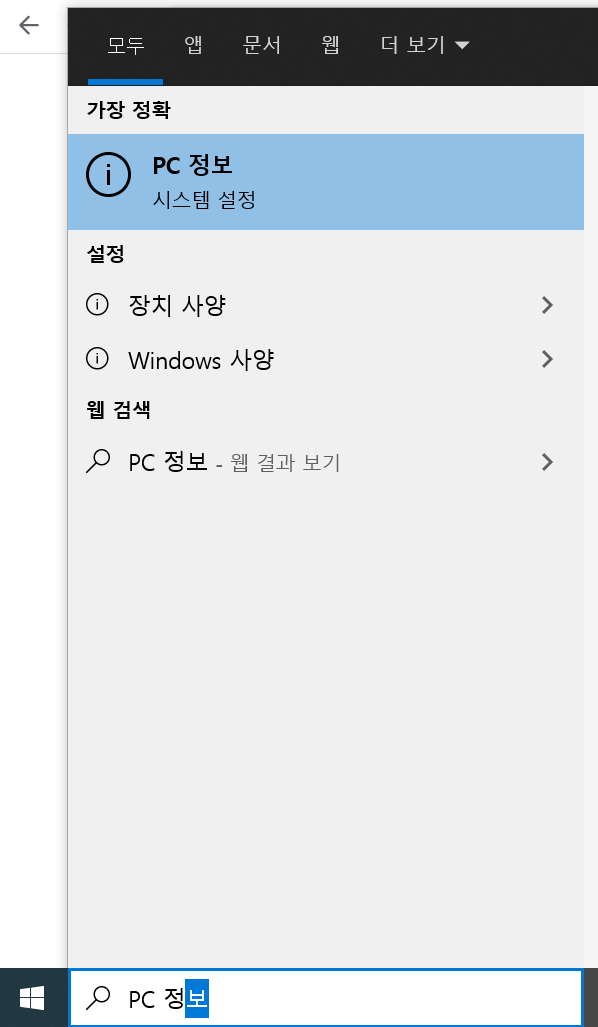

결론적으로 이 환경의 경우는
PyAudio‑0.2.11‑cp37‑cp37m‑win_amd64.whl 파일을 다운로드하면 됩니다.
cmd창이 현재 실행되는 위치로. whl파일을 옮깁니다.
예시에는 C:\Users\PC> 라고 쓰여 있으니, C:\Users\PC 로 파일을 복사하겠습니다.
그리고, 다음 명령을 수행합니다.
$ pip install <다운로드받은 .whl 파일명>예) pip install PyAudio-0.2.11-cp37-cp37m-win_amd64.whl
참고) MacOS 사용자라면, 다음과 같이 설치하세요.
$ pip install SpeechRecognition
$ brew install portaudio
$ pip install pyaudio
사전 준비가 완료되었습니다.
3. 사전 지식 쌓기
Jarvis 프로젝트 진행에 앞서 지식을 쌓을 내용은 다음과 같습니다.
3-1) 음성인식 (STT)
Kakao OpenAPI중에 음성인식 기능이 있습니다.
사용을 위해서는 애플리케이션에 음성기능을 활성화합니다.
| > 순서 : 내애플리케이션 > {애플리케이션 선택} > 음성 |
상태를 'on'으로 변경시 팝업창이 뜨면, 사용목적에 '테스트'라고 입력합니다.
상단 메뉴에 [문서]버튼을 눌러 화면을 아래로 내려보면, "인공지능 API가이드"라는 부분이 있습니다.
비전, 포즈, 번역, 음성과 같은 기능을 제공합니다. 이번장에서는 음성 기능을 사용해보겠습니다. OpenAPI 사용을 위해 음성의 REST API를 클릭합니다.

음성과 관련해서는 '음성 인식'과 '음성 합성'을 지원하고 있습니다. 음성인식이 STT에 해당합니다. 하여, 이번장에서는 음성인식만 다루도록 하겠습니다. 설명을 보면, 주의 사항이 보입니다. 음성 데이터는 "Mono channel, 16000Hz samplerate, 16bit deapth인 RAW PCM 포맷만 지원한다"고 되어 있습니다.

이제 OpenAPI를 사용할 땐, Requst와 Response를 본다는 점이 익숙해지셨나요?
Request입니다. POST와 Host 정보를 이용해서 Request URL을 만듭니다. Quthorization은 앱키만 있으면 되네요.
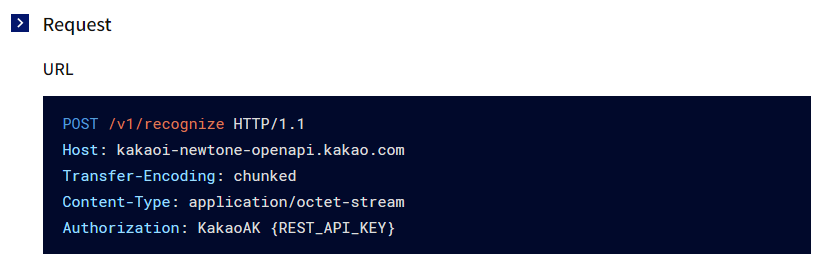
Response입니다. 여러가지 정보가 남기는데, 최종 음성인식 결과를 의미하는 finalResult만 사용하겠습니다.
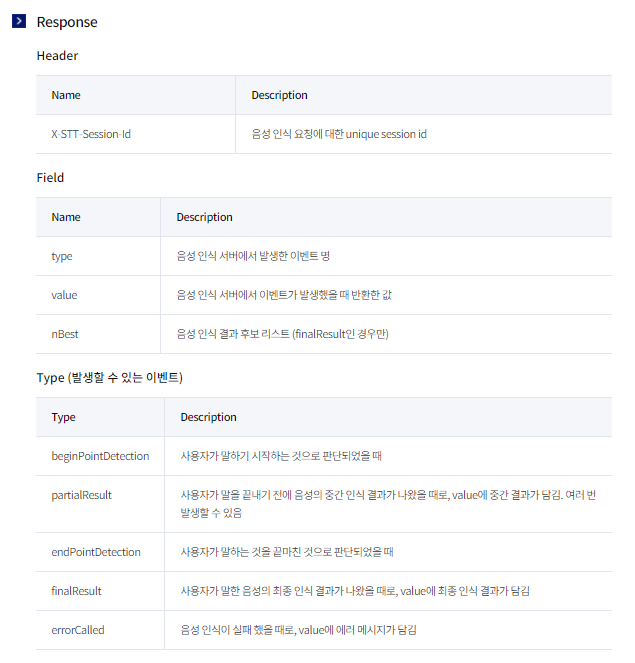
만약 내용이 어렵게 느껴지시면, 문서에 기재되어 있는 예시를 먼저 보는 것을 권장합니다.
자 이제 사용해볼까요? Request에 음성을 전달 할때, RAW 포맷만 지원한다고 합니다.
코드
import requests
import json
# 함수 정의부
def kakao_stt(app_key, stype, data):
if stype == 'file':
filename = data
with open(filename, "rb") as fp:
audio = fp.read()
else:
audio =data
headers = {
"Content-Type": "application/octet-stream",
"Authorization": "KakaoAK " + app_key,
}
# 카카오 음성 url
kakao_speech_url = "https://kakaoi-newtone-openapi.kakao.com/v1/recognize"
# 카카오 음성 api 요청
res = requests.post(kakao_speech_url, headers=headers, data=audio)
# 요청에 실패했다면,
if res.status_code != 200:
text=""
print("error! because ", res.json())
else: # 성공했다면,
#print("음성인식 결과 : ", res.text)
#print("시작위치 : ", res.text.index('{"type":"finalResult"'))
#print("종료위치 : ", res.text.rindex('}')+1)
#print("추출한 정보 : ", res.text[res.text.index('{"type":"finalResult"'):res.text.rindex('}')+1])
result = res.text[res.text.index('{"type":"finalResult"'):res.text.rindex('}')+1]
text = json.loads(result).get('value')
return text
# 함수 호출부
KAKAO_APP_KEY = "<REST_API 앱키를 입력하세요>"
AUDIO_FILE = "res/jarvis/hello.wav"
text = kakao_stt(KAKAO_APP_KEY, "file", AUDIO_FILE)
print(text)
실행 결과
안녕하세요 오늘도 멋진 하루 되세요
코드 설명
5 라인 : 음성인식을 하는 함수를 정의 합니다. input은 app_key, stype, data를 주어야 하는데요, stype은 "file" 또는 "stream" 2가지 종류를 지원합니다. stype이 "file"인 경우 data에 filename을 주고, "stream"인 경우는 audio data를 줍니다.
6~11라인 : stype이 'file'인 경우 data값을 filename으로 사용합니다. 그리고 파일을 open하고, read한 결과를 음성인식 Request에 input으로 설정합니다. 만약, stype이 "stream" 이라면, data가 audio data를 의미합니다.
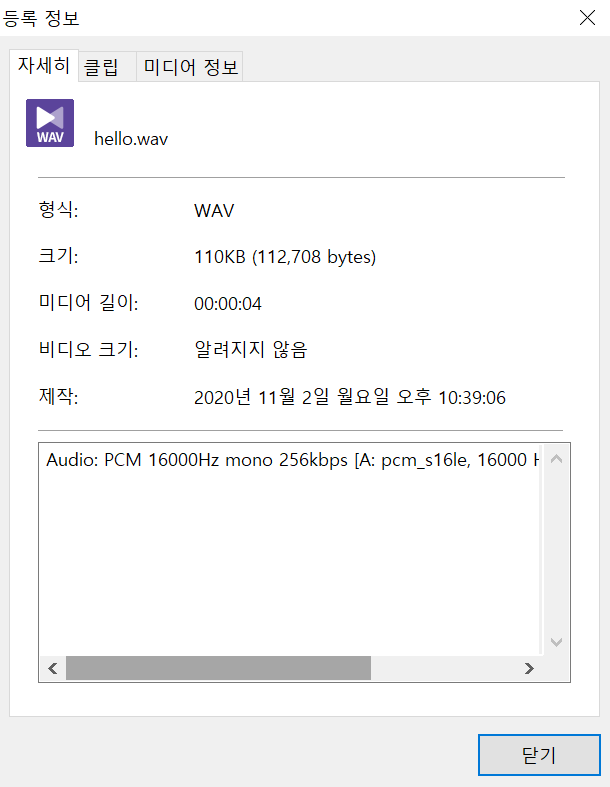
카카오 음성의 경우 RAW포맷만 지원을 하므로 파일을 사용할 경우는 확장자가 .wav인 파일이고, 16000Khz, mono channel 인지 확인이 필요합니다. 확인하는 방법은 음악을 듣는 GOM player나, KMPlayer등에서 확인할 수 있습니다.
아래 그림은 "res/jarvis/hello.wav" 파일을 KMPlayer로 확인한 결과입니다. 16000에 mono 라고 되어 있네요.
file이 아닌 mic로 입력 받은 데이터를 사용하는 경우, PCM RAW 형태이며 Samplingrate는 음성 적재 전 설정을 하면 됩니다.
13~16라인 : Request 설명을 보고, "Content-Type" 값과 "Authorization"을 설정합니다.
19라인 : Request의 "POST"와 "HOST" 정보를 보고, URL을 설정합니다.
21라인 : 음성인식을 요청합니다.
31라인 : 결과는 res.text에 담기고, 문자열 형태입니다. Response를 보면 다양한 결과 값을 주지만, 최고의 결과만 사용하면 되므로, finalResult만 가지고 오면 됩니다.
아래와 같은 표현은 res.text에서 해당 문자열('{"type":"finalResult"')과 일치하는 시작 위치를 알려줍니다.
res.text.index('{"type":"finalResult"')그리고 아래와 같은 표현은 res.text에서 해당문자열('}')과 가장 마지막에 일치하는 위치를 알려줍니다.
res.text.rindex('}')+1원하는 문자열의 시작 위치와, 마지막 위치를 알게 되었으므로, res.text에서 추출하면 됩니다. res.text[시작위치:마지막위치+1] 이 되어야 하므로, 아래와 같은 코드가 만들어진 것입니다.
res.text[res.text.index('{"type":"finalResult"'):res.text.rindex('}')+1]만약 내용이 이해가 잘 되지 않는다면, 27~30라인의 주석문을 풀어, 각 단계별 결과를 출력해보세요. 그럼 이해가 더 쉽게 될 것입니다.
37~40라인 : 파일을 읽어 STT를 수행하고, 그 결과를 출력합니다.
여기서는 오디오 파일을 이용한 STT만 테스트하였습니다. 이제 마이크로 입력받은 audio stream를 직접 변환해 보겠습니다.
3-2) 마이크(mic)로 음성 수집하기
마이크로 음성을 수집해보겠습니다.
코드
import speech_recognition as sr
# 함수 정의부
def get_speech():
# 마이크에서 음성을 추출하는 객체
recognizer = sr.Recognizer()
# 마이크 설정
microphone = sr.Microphone(sample_rate=16000)
# 마이크 소음 수치 반영
with microphone as source:
recognizer.adjust_for_ambient_noise(source)
print("소음 수치 반영하여 음성을 청취합니다. {}".format(recognizer.energy_threshold))
# 음성 수집
with microphone as source:
print("Say something!")
result = recognizer.listen(source)
audio = result.get_raw_data()
return audio
# 함수 호출부
audio = get_speech()
text = kakao_stt(KAKAO_APP_KEY, "stream", audio)
print("음성 인식 결과 : " + text)
실행 결과
Say something!이라는 글자가 나오면, 또박또박 천천히 말해보세요. 여러분이 했던 말이 그대로 Text로 나왔나요?
소음 수치 반영하여 음성을 청취합니다. 59.554952545283726
Say something!
음성 인식 결과 : 주식 보고서 보내줘
코드 설명
1라인 : 필요한 라이브러리를 import 합니다.
4~23라인 : 음성을 수집할 함수를 정의합니다. 입력은 없으며, 마이크로 음성을 입력받고 그 음성 데이터를 출력하는 함수입니다.
6라인에서 마이크에서 음성을 추출할 객체를 생성합니다.
9라인에서는 마이크 사용을 위한 객체를 선언하는데요, 이때 sampling rate를 입력합니다. 현재 16KHz로 설정을 하였고, 그 이유는 Kakao STT OpenAPI의 제한 사항 때문입니다.
12~14라인은 마이크가 소음 수치를 반영하여, 더욱 음성을 명확하게 받아들이게 합니다.
17~20라인에서 음성(소리)이 들어오길 기다립니다. 여러분이 말을 하면, 그 값을 audio변수에 담습니다. 그리고 담긴 값을 22라인에서 return 합니다.
25~26라인 : 음성 수집 함수를 호출합니다. 수집만으로는 잘 수집이 되었는지, 아닌지를 알 수 없으므로 kakao_stt()를 호출하여, 수집된 음성의 내용을 확인합니다.
마이크를 연동하여, 본인이 말한 내용이 그대로 Text로 나오니 너무나 신기합니다.
자, 이제 Jarvis 프로젝트를 완성해보시죠.
4. 구현
Jarvis 프로젝트의 구현 순서는 아래와 같습니다.
음성을 통해 제어하기 위해 컴퓨터에 내장된 마이크(mic)로 음성을 수집합니다. 카카오의 STT OpenAPI로 수집된 음성을 Text로 변환합니다. Text를 분석하여 "날씨"라는 글자가 있다면, "날씨 정보를 이용한 맛집 추천 프로젝트"가 수행되고, "주식"이라는 글자가 있다면, "주식 분석 보고서 자동화 프로젝트"가 수행됩니다.

두 프로젝트의 소스 코드를 정리하는 과정이 있습니다. 다소 복잡해 보일 수 있지만, 어렵지는 않습니다. 천천해 따라 해 보세요.
[구현 순서]
점진적으로 구현을 완성해 나가 봅시다.
| Step1 | 구현 코드 정리 하기 - '날씨' |
| Step2 | 구현 코드 정리하기 - '주식' |
| Step3 | Jarvis 프로젝트 |
Step1) 구현 코드 정리 하기 - '날씨'
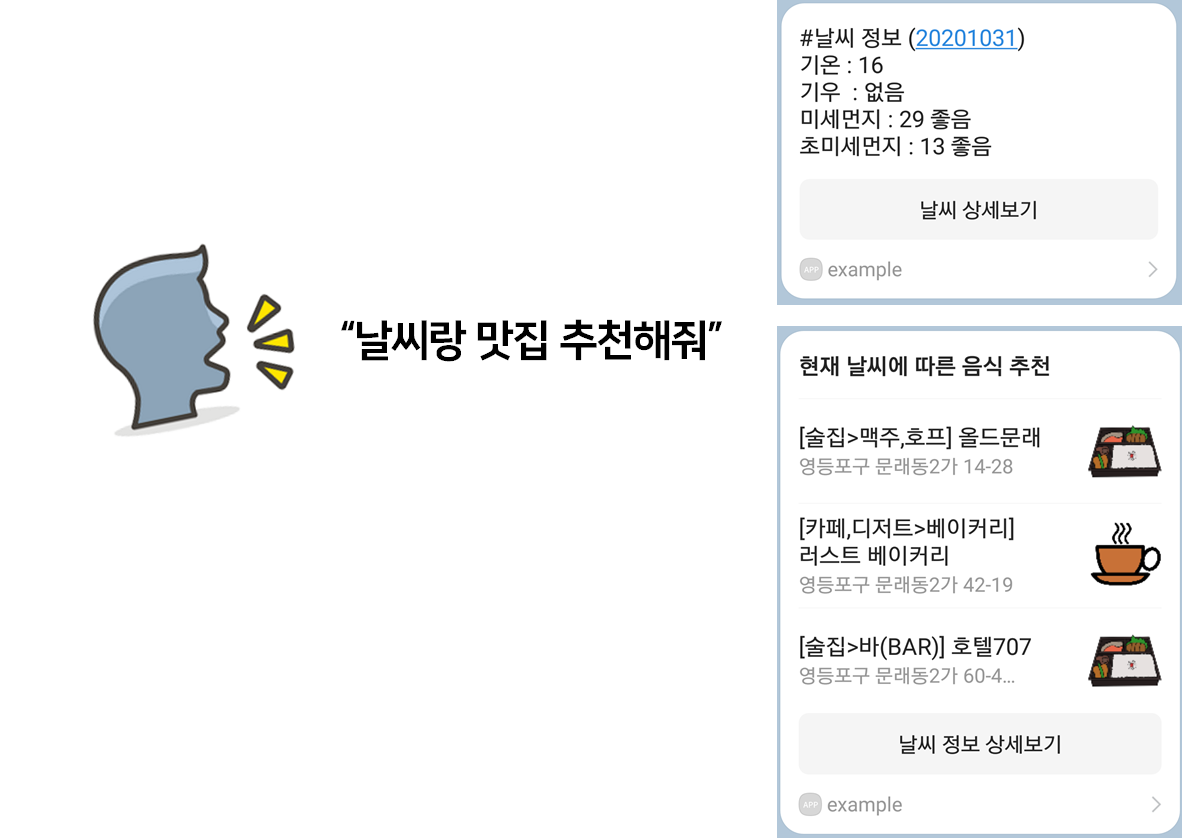
"날씨랑 맛집 추천해줘"와 같이 문장에 "날씨"가 있다면, 날씨 정보를 이용한 맛집 추천 프로젝트가 수행됩니다. 해당 장의 구현 코드 중에 "4. 구현" 부분만 사용할 것입니다.
food_recommender.ipynb 파일을 복사하고, jarvis_food_recommender.ipynb로 이름을 변경하고 이제부터는 jarvis_food_recommender.ipynb 파일로 작업을 하겠습니다.

'4. 구현' 전까지는 사용하지 않는 코드이니 삭제합니다.
그리고, 꼭 잊지 말고 수정해 두어야 할 부분은 "4. 구현"에서 사용하고 있는 공공데이터 포털의 service_key, 네이버의 client_id와 secret, 카카오의 app_key 값들입니다. 수정이 되어 있지 않다면, 꼭 값을 세팅해주세요.
이후 주피터 노트북에서 File > Download as > Python(. py)를 눌러 jarvis_food_recommender.py 파일을 다운로드한 후, 현재 작업 중인 폴더 위치로 옮겨 줍니다.
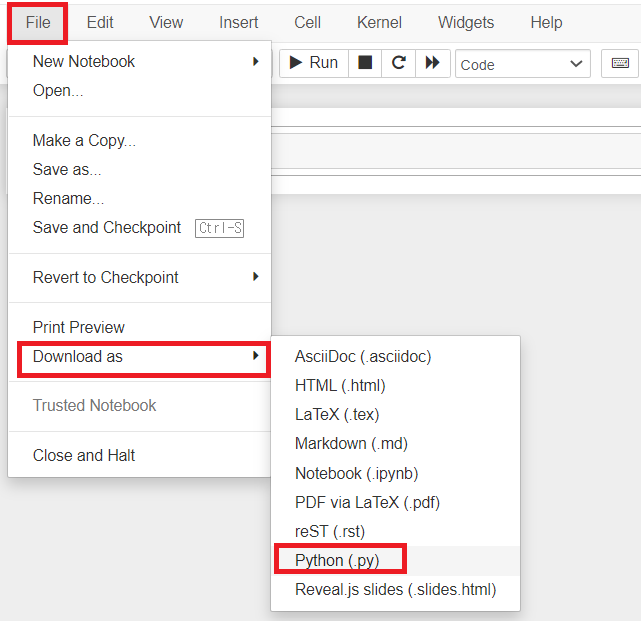
동일한 폴더에 두 파일이 있으면 완성! 이제는 .py 파일만 사용합니다.
주피터 노트북에서 jarvis_food_recommender.py 파일을 열고, do() 함수로 정의합니다. 코드를 전체 선택해서 키보드에 있는 [Tab] 키로 일괄 들여 쓰기를 하고, 10라인에 def do(): 라고 기재하는 것이 제일 간단합니다.
수정이 잘 되었다면, 아래와 같은 모습을 띕니다.

작업이 잘 되었는지 확인을 위해 새로운 파일을 열어 아래와 같이 코딩합니다.
코드
import jarvis_food_recommender
jarvis_food_recommender.do()
실행 결과
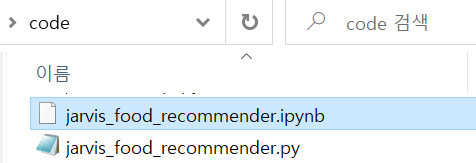
프로젝트가 전체 수행되어, 카카오 메시지가 전송되었습니다.
코드 설명
1 라인 : jarvis_food_recommender 모듈을 import 합니다.
2 라인 : jarvis_food_recommender.do()로 함수를 호출합니다.
(참고) 한 번에 완벽하게 수행이 되면 좋지만, 여러 이유로 수행이 안돼서. py 파일을 수정할 수도 있습니다. 파일을 수정한 후, 아무리 jarvis_food_recommender.do()를 호출해도 수정된 내용이 적용되지 않는다는 것을 알게 될 텐데요. 그 이유는 모듈을 reload 해주어야 하기 때문입니다. reload 하는 방법입니다.
코드
from imp import reload
reload(jarvis_food_recommender)
import jarvis_food_recommender
jarvis_food_recommender.do()
Step2) 구현 코드 정리하기 - '주식'
Jarvis 프로젝트는 음성 중에 "주식"이라는 단어가 있으면 주식 분석 보고서 자동화 프로젝트가 수행됩니다. 해당 장의 구현 코드 중에 "4. 구현" 부분만 사용할 것입니다. stock_report.ipynb 파일을 복사하고, jarvis_stock_report.ipynb 로 이름을 변경하고, 최종적으로 jarvis_stock_report.py를 만듭니다. "4. 구현"에 메일을 주고 받을 sender, receiver의 값 세팅을 잊지 말고 작업해주세요.
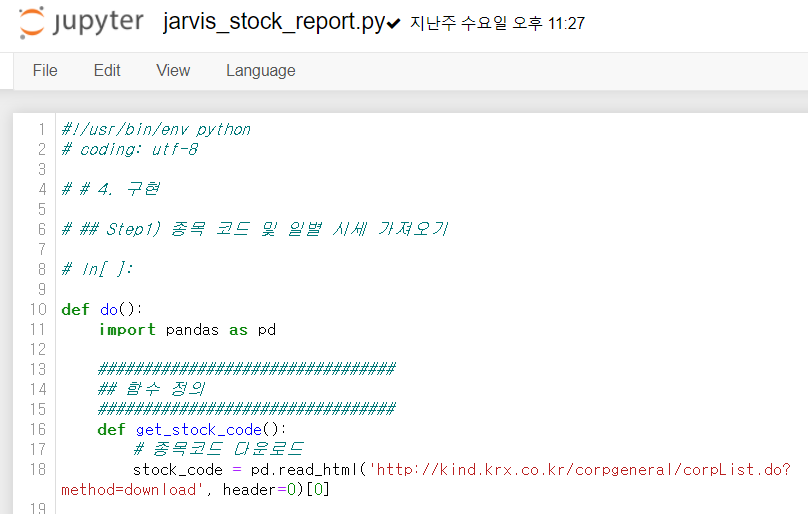
만드는 방법은 Step1)과 동일합니다. 그래서 과정은 기재하지 않고, 최종 파일의 모습만 보여드립니다.
작업이 잘 되었는지 확인을 위해 새로운 파일을 열어 아래와 같이 코딩합니다.
코드
import jarvis_stock_report
jarvis_report_jarvis.do()
실행 결과
프로젝트가 전체 수행되어, 메일로 주식 보고서가 전달되었습니다.

코드 설명
1 라인 : jarvis_food_recommender 모듈을 import 합니다.
2 라인 : jarvis_food_recommender.do()로 함수를 호출합니다.
이제, 각각을 조합해서 Jarvis를 완성해보겠습니다.
Step3) Jarvis
음성을 분석해서 '날씨'라는 글자가 있다면, "날씨 정보를 이용한 맛집 추천 프로젝트"를 "주식"이라는 글자가 있다면, "주식 분석 보고서 자동화 프로젝트"를 수행합니다.
코드
import jarvis_food_recommender
import jarvis_stock_report
KAKAO_APP_KEY = "<REST_API 앱키를 입력하세요>"
KEYWORD_STOCK = '주식'
KEYWORD_WEATHER = '날씨'
# 음성 수집
audio = get_speech()
# STT
command = kakao_stt(KAKAO_APP_KEY, "stream", audio)
print("명령어 : " + command)
print('명령을 수행합니다.')
# 음성 분석
if KEYWORD_WEATHER in command:
print('날씨를 파악하여 맛집을 추천합니다.')
jarvis_food_recommender.do()
elif KEYWORD_STOCK in command:
print('주식 보고서를 메일로 전송합니다.')
jarvis_stock_report.do()
else:
print('명령을 알 수 없습니다.')
실행 결과
'날씨랑 맛집 알려줘'
소음 수치 반영하여 음성을 청취합니다. 48.94442598560941
Say something!
명령어 : 날씨랑 맛집 알려줘
명령을 수행합니다.
날씨를 파악하여 맛집을 추천합니다.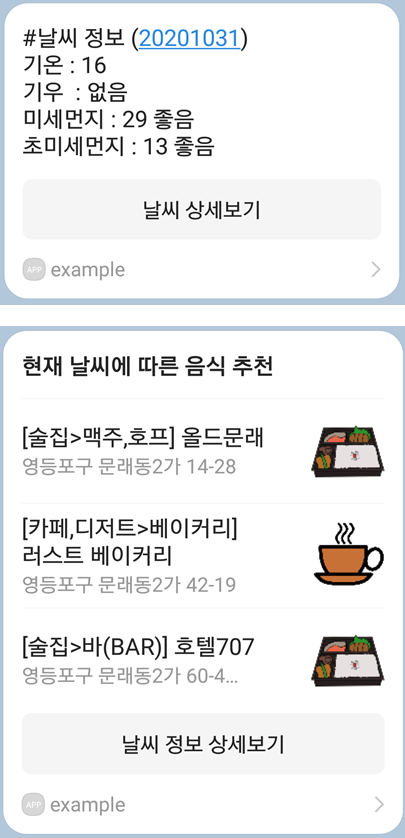
'주식 보고서 보내줘'
소음 수치 반영하여 음성을 청취합니다. 49.22035454252694
Say something!
명령어 : 주식 보고서 보내줘
명령을 수행합니다.
주식 보고서를 메일로 전송합니다.
코드 설명
1~2 라인 : Jarvis가 수행할 모듈을 import합니다.
4라인 : 카카오 앱 키를 설정합니다.
6~7라인 : 감지해야 할 단어를 설정합니다. Text 중에서 해당 단어만 있다면, 명령을 수행하도록 하기 위함입니다.
10라인 : 마이크를 켜고, 음성을 수집합니다.
13라인 : STT를 수행하고, 변환된 Text를 command 변수에 담습니다.
18~25라인 : Text내용 중에 감지할 단어가 있다면, 해당 명령을 수행합니다.
5. 요약정리
이번장에서는 Jarvis 프로젝트를 수행해 보았습니다. 개인 비서처럼 말만 하면 원하는 프로그램을 수행합니다. 음성 제어를 위해서 마이크(mic)로 음성을 수집하고, 카카오 STT OpenAPI로 Text로 변환합니다. 이 Text를 분석하여 "날씨"라는 글자가 있다면, "날씨 정보를 이용한 맛집 추천 프로젝트"가 수행되고, "주식"이라는 글자가 있다면, "주식 분석 보고서 자동화 프로젝트"가 수행됩니다.
카카오 이외에도 구글, ETRI 등에서도 STT기능을 지원하고 있습니다. 다양한 STT OpenAPI를 적용해보면서 어느 회사의 서비스가 더 성능이 좋은지 비교해보면 재미있겠네요. 그리고, 이번 장에서는 2개의 프로젝트만 연결하였지만, 앞에서 진행한 다른 프로젝트들도 연결해보세요. 개인 비서 역할을 톡톡히 할 것입니다.
생활 속에 불편함을 해소하기 위해 파이썬이라는 프로그램 언어를 사용하였고, 다양한 프로젝트와 여러 종류의 OpenAPI를 사용하면서 진행해보았는데, 어떠셨나요? 이제 파이썬 사용에 자신감이 붙으셨나요? 그리고, 파생되는 더 좋은 아이디어가 마구 생기나요?
ㅁ 꿀팁!
step1) TTS로 소리파일 만들기
typecast
타입캐스트는 인공지능 딥러닝 기술을 활용해 특정인의 목소리 스타일, 특징 등을 학습하여 누구든지 개성과 감성이 담긴 오디오 컨텐츠를 생성할 수 있는 서비스입니다.
typecast.ai
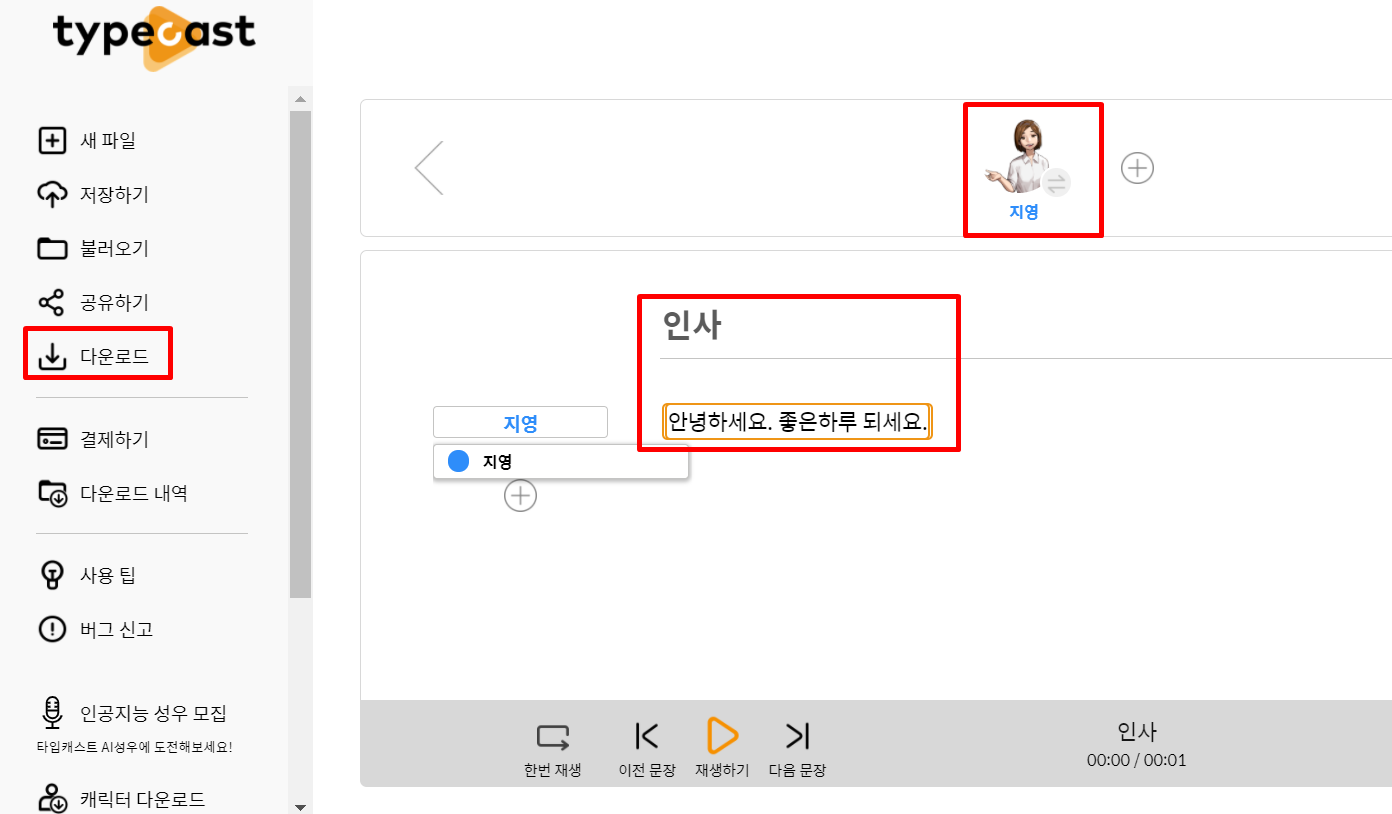
step2) 라이브러리 설치
$ pip install playsoundstep3) 라이브러리 설치
from playsound import playsound
playsound('res\\jarvis\\hello.wav')도움이 되셨다면, 좋아요 / 구독 버튼 눌러주세요~
저작물의 저작권은 작성자에게 있습니다.
공유는 자유롭게 하시되 댓글 남겨주세요~
상업적 용도로는 무단 사용을 금지합니다.
끝까지 읽어주셔서 감사합니다^^
'오늘 배워 오늘 쓰는 OpenAPI > 프로젝트' 카테고리의 다른 글
| 카카오 이미지검색 OpenAPI로 연예인 사진 모으기 (5) | 2020.10.04 |
|---|---|
| [Python] 주식 분석 보고서 만들기 (자동화) (17) | 2020.06.13 |
| [Python-pptx] 부동산 지역 분석 보고서 만들기 (자동화) (0) | 2020.05.23 |
| [Python] Selenium 사용법 + 구글 검색 자동화 (11) | 2020.05.16 |
| [Python] Selenium - 동적페이지 크롤링 (2) | 2020.05.16 |



