
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 구글
- 자동화
- 간단한파이썬게임
- 인공지능
- 구글일정
- 카카오
- 기본기
- 파이썬
- 오늘배워오늘쓰는
- 딥러닝
- 빅데이터
- 파이썬게임
- kakao
- Python
- 파이썬독학
- Ai
- 음성인식
- 머신러닝
- STT
- Selenium
- 파이썬게임만들기
- Quickstart
- 웹크롤링
- 파이썬간단한게임
- OpenAPI
- 업무자동화
- 크롤링
- 소스코드
- 독학
- 구글캘린더
- Today
- Total
ai-creator
네이버 속보 뉴스 요약 프로젝트 - 웹크롤링 + OpenAPI 활용 본문
오.오.쓰 에 오신 것을 환영합니다.
[네이버 뉴스 요약 프로젝트] 입니다.
아래와 같은 순서로 배워보겠습니다.
1. 학습 목표
세상엔 너무 많은 뉴스가 있고, 그것을 다 읽을 시간이 충분치 않습니다. 특히나 요즘은 동영상을 많이 보다 보니, 정적인 글을 읽을 때 집중이 잘 되지 않더라고요. 때로는 출퇴근 또는 이동시간에 스마트폰으로 뉴스를 보려고 하면 광고들이 많아서 의도치 않게 광고를 클릭하게 되고, 어떨 땐 이상한 바로가기 앱이 만들어지기도 합니다. 뉴스를 읽으려던 의지는 어느새 불편함으로 연결되죠.

하지만, 이러한 불편함을 감수하더라도 뉴스의 필요성은 누구나 알고 있을 거 같아요.
그럼 이런 문제를 해결하기 위해서는 어떻게 해야 할까요?
정보는 많고, 시간이 없다면?
이러한 불편함을 해소하기 위해서 중요한 뉴스만 요약해서 보내주면 어떨까요?
네이버 뉴스를 분야별로 요약해서 카카오 메시지로 받아 시간을 절약해보는 프로젝트! 근사하지 않나요?
[구현 순서]
뉴스 요약 프로젝트를 위한 구현 순서는 아래와 같습니다.

네이버 뉴스를 크롤링하고,
gensim 라이브러리를 통해 뉴스 본문의 긴 글을 요약합니다.
그리고, 마지막으로 카카오톡 메시지로 정보를 전달 합니다.
[최종 결과]
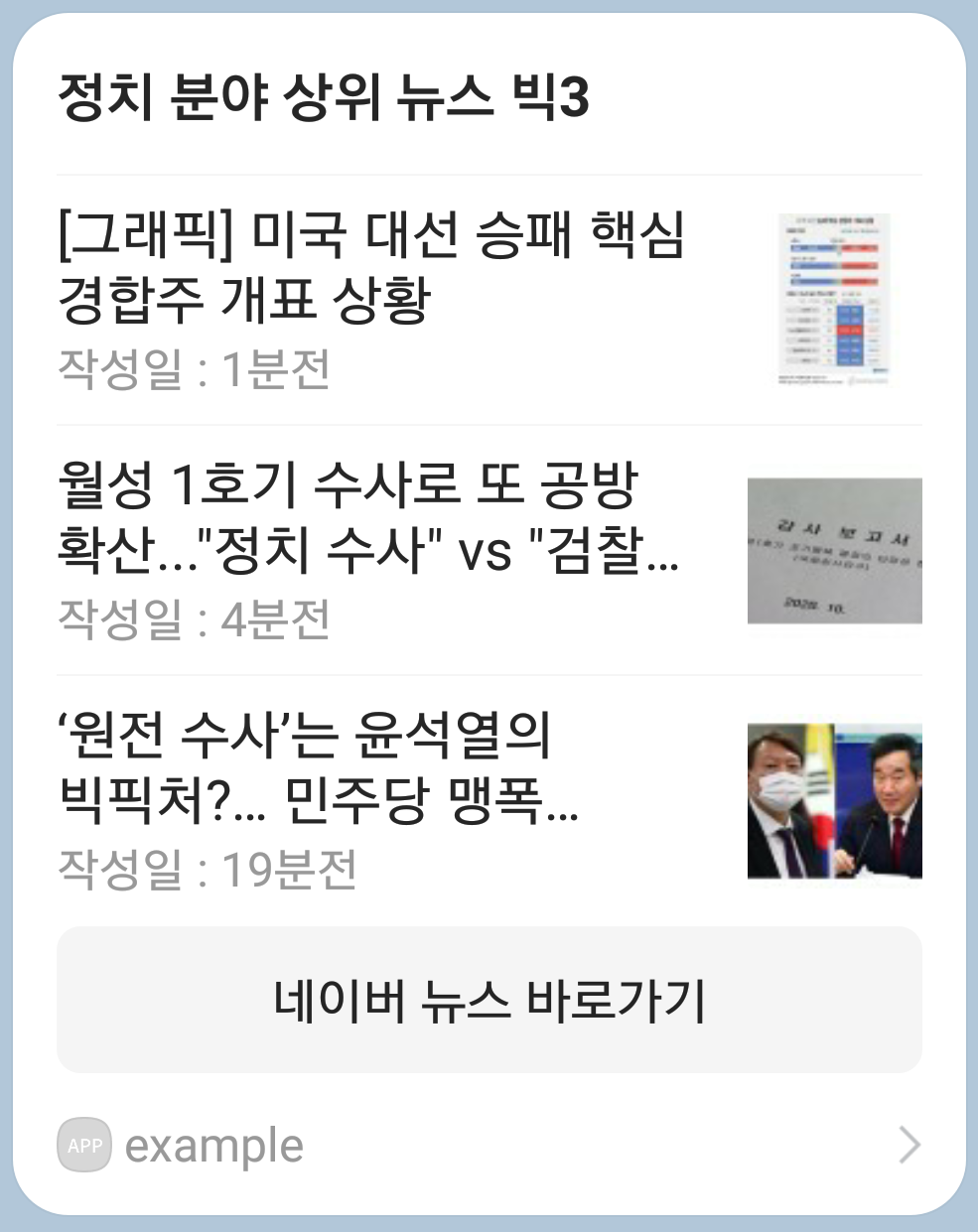

※ 실행되는 날짜에 따라 뉴스 내용이 변하므로, 실행하는 시점에 따라 결과가 동일하지 않습니다.
[언어 & 환경(IDE)]
Python 3.7 & Jupter notebook
[프로젝트 리소스 및 소스 코드]
- news_summarize.ipynb : 뉴스 요약 프로젝트 구현 코드
- kakao_utils.py : 카카오 메시지 전송을 위한 유틸리티 구현 코드
- res/kakao_message/kakao_token.json : 카카오 access token과 refresh token이 관리되는 파일
> 접속 URL : drive.google.com/drive/folders/10KXyPrJ_KEesvAvjnMpx1DS_md7gaN6H?usp=sharing
ai-creator 공유폴더 - Google 드라이브
drive.google.com
※ 프로젝트에 필요한 리소스 및 소스코드의 경로 구성은 자유롭게 설정하면 됩니다. 그러나, 아래 설명되어 있는 코드 구현이 제시된 구성으로 되어 있으니, 동일하게 경로와 파일명으로 구성해 둔다면 별다른 코드 수정 없이 실행해 볼 수 있습니다.
2. 사전 준비
세 가지 사전 준비가 필요합니다.
먼저, '나에게 카카오톡 보내기'(Link)의 사전 준비를 완료하셔야 합니다.
다음은 설치가 필요한 라이브러리 목록입니다.
$ pip install gensim BeautifulSoup4 lxml requestsgensim은 뉴스를 요약하는 용도로 사용합니다.
BeautifulSoup4와 lxml은 html 구조를 파싱 하고, 관리를 편하게 돕는 역할을 합니다.
requests는 서버에게 url에 해당하는 html을 요청하거나, 카카오 OpenAPI의 REST API를 사용하기 위함입니다.
마지막으로 카카오 개발자 사이트에서 만든 애플리케이션 설정입니다.
카카오 메시지에서 버튼을 클릭할 경우, 네이버 뉴스 화면으로 이동하려 합니다. 이를 위해 애플리케이션에 설정을 추가해줍니다.
| 순서 : 카카오 개발자 사이트 접속 > "내 애플리케이션" 클릭 > 앱 설정 > 플랫폼 > Web에서 [수정]버튼 클릭 > https://news.naver.com 추가 |

3. 사전 지식 쌓기
뉴스 요약 프로젝트를 수행하기 위해 지식을 쌓을 내용은 다음과 같습니다.
3-2) 네이버 뉴스 구조 이해하기 - 섹션별 접속 주소(URL) 확인
3-3) 네이버 뉴스 구조 이해하기 - 상위 3개의 뉴스 메타 정보 확인
네이버 영화 리뷰 크롤링(Link) 을 따라 해 보셨다면, 더 쉽게 이해할 수 있습니다.
3-1) User-Agent 확인하기
크롤링을 하기 위해 만든 코드가 있다고 가정해 봅시다. 그런데, 방금까지 잘되던 코드가 갑자기 안 되는 경우가 발생했습니다. 이럴 땐 어떻게 해야 할까요? requests.get()으로 받은 에러코드 및 html 코드가 정상적인지 확인이 필요합니다.
혹시 전달받은 html 코드가 아래와 같이 나온다면?

정상적으로 사람이 클릭해서 서버에 접속한 것이 아니라, 불법 프로그램에 의한 접속으로 판단해서 크롤링을 막은 경우에 해당합니다. 그러므로, 프로그램에서 해야 할 일은 사용자가 직접 접속했다는 정보를 추가하여 문제를 해결할 수 있습니다. 그 방법은 user-agent 정보를 header에 넣어주어 해결할 수 있습니다. 이를 위해 먼저 user-agent정보를 확인해야 하는데요, 아래 사이트에 접속하여 나타나는 정보를 copy 합니다.

그 후 header에 정보를 넣어서 requests.get()을 시도하면 정상적으로 동작하게 됩니다.
# 해당 분야 상위 뉴스 HTML 가져오기
headers = {'User-Agent' : '<복사한 user-agent값 대체>'} # ex. 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ...생략...'
res = requests.get(news_link, headers = headers)
print(res.text)간헐적으로 발생하는 현상이므로, 초반부터 이런 현상을 막기 위해 user-agent값을 확인하시고 이후에 나오는 코드에 해당 값을 넣어서 사용하시길 추천합니다.
3-2) 네이버 뉴스 구조 이해하기 - 섹션별 접속 주소(URL) 확인
크롤링을 하기 위해서는 사이트의 URL과 HTML구조를 알아야 합니다.
먼저 네이버 뉴스 (news.naver.com/)에 접속하고, 제일 빠르게 전달되는 뉴스만 보기 위해 "속보"를 클릭합니다.

섹션별로 뉴스가 있습니다.
정치, 경제, 사회별로 접속주소(url)의 변화를 확인해 봅시다.

변화하는 부분과 고정되는 부분이 보이나요? sid1뒤의 값이 정치는 100, 경제는 101, 사회는 102
# 정치 섹션을 눌렀을때, url 주소
https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1=100
# 경제 섹션을 눌렀을때, url 주소
https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1=101
# 사회 섹션을 눌렀을때, url 주소
https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1=102그럼 각 분야별 접속 주소(url)를 어떻게 구현할 수 있을까요?
코드
for sid in ['100', '101', '102']:
# 해당 분야 상위 뉴스 목록 주소
sec_url = "https://news.naver.com/main/list.nhn?mode=LSD&mid=sec" \
+ "&sid1=" \
+ sid \
print("section url : ", sec_url)실행 결과
분야별 url 결과입니다.
section url : https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1=100
section url : https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1=101
section url : https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1=102코드 설명
1라인 : 3개의 섹션(정치, 경제, 사회)으로 이루어지며, sid1= 다음의 값이 각각 100, 101, 102로 되어 있으므로, 세 값을 리스트로 만듭니다. 그리고, 반복문을 통해서 sid가 사용될 수 있도록 합니다.
3~5라인 : 변화하는 부분에 맞춰 섹션별 url을 만듭니다.
이렇게 만들어진 접속 주소로 접속하고, 상위 3개의 뉴스 메타 정보를 가지고오면 됩니다.
3-3) 네이버 뉴스 구조 이해하기 - 상위 3개의 뉴스 메타 정보 확인
상위 3개 뉴스 메타 정보를 크롤링하기 위해서 html구조를 살펴봅시다.
'정치' 섹션의 뉴스 메타 정보를 가져올 수 있다면, '경제', '사회'도 동일한 구조로 되어 있으니 반복 수행을 한다면 섹션별 메타정보를 가져올 수 있습니다.
정치 섹션의 상위 3개의 메타 정보를 크롤링해보겠습니다.

<ul>의 class가 "type06_headline"인 <li>를 3개 가지고 오면 되겠습니다.
그 후,
<a>의 href로 뉴스 본문을
<a>의 img의 alt를 뉴스 제목을
class가 date인 것을 작성일 정보로 가져옵니다.
코드
import requests
from bs4 import BeautifulSoup
import bs4.element
import datetime
# BeautifulSoup 객체 생성
def get_soup_obj(url):
headers = {'User-Agent' : '<복사한 user-agent값 대체>'}
res = requests.get(url, headers = headers)
soup = BeautifulSoup(res.text,'lxml')
return soup
default_img = "https://search.naver.com/search.naver?where=image&sm=tab_jum&query=naver#"
for sid in ['100']:#, '101', '102']:
# 해당 분야 상위 뉴스 목록 주소
sec_url = "https://news.naver.com/main/list.nhn?mode=LSD&mid=sec" \
+ "&sid1=" \
+ sid
print("section url : ", sec_url)
# 해당 분야 상위 뉴스 HTML 가져오기
soup = get_soup_obj(sec_url)
# 해당 분야 상위 뉴스 3개 가져오기
lis3 = soup.find('ul', class_='type06_headline').find_all("li", limit=3)
for li in lis3:
# title : 뉴스 제목, news_url : 뉴스 URL, image_url : 이미지 URL
news_info = {
"title" : li.img.attrs.get('alt') if li.img else li.a.text.replace("\n", "").replace("\t","").replace("\r","") ,
"date" : li.find(class_="date").text,
"news_url" : li.a.attrs.get('href'),
"image_url" : li.img.attrs.get('src') if li.img else default_img
}
print(news_info)실행 결과
정치 섹션 상위 3개의 뉴스 메타 정보 결과입니다.
section url : https://news.naver.com/main/list.nhn?mode=LSD&mid=sec&sid1=100
{'title': '[그래픽] 미국 대선 승패 핵심 경합주 개표 상황', 'date': '1분전', 'news_url': 'https://news.naver.com/main/read.nhn?mode=LSD&mid=sec&sid1=100&oid=001&aid=0011999084', 'image_url': 'https://imgnews.pstatic.net/image/origin/001/2020/11/07/11999084.jpg?type=ofullfill106_72'}
{'title': '월성 1호기 수사로 또 공방 확산..."정치 수사" vs "검찰 흔들기"', 'date': '3분전', 'news_url': 'https://news.naver.com/main/read.nhn?mode=LSD&mid=sec&sid1=100&oid=052&aid=0001511434', 'image_url': 'https://imgnews.pstatic.net/image/origin/052/2020/11/07/1511434.jpg?type=ofullfill106_72'}
{'title': '‘원전 수사’는 윤석열의 빅픽처?… 민주당 맹폭 “검찰총장은 선출된 국민의 대표 아니다”', 'date': '19분전', 'news_url': 'https://news.naver.com/main/read.nhn?mode=LSD&mid=sec&sid1=100&oid=022&aid=0003520846', 'image_url': 'https://imgnews.pstatic.net/image/origin/022/2020/11/07/3520846.jpg?type=ofullfill106_72'}코드 설명
1~4라인 : 필요한 라이브러리를 import 합니다.
6~12라인 : url을 요청해서 beautifulsoup 객체를 생성하는 함수입니다. url을 input으로 받고, beautifulsoup 객체를 output으로 전달해줍니다. beautifulsoup의 동작방법을 이해하고 싶다면, 네이버 영화 리뷰 크롤링(Link)을 확인하세요.
13라인 : 뉴스 중 이미지가 없는 뉴스도 있습니다. 이 경우를 위해서 임시 이미지를 설정해 둡니다.
14~34라인 : 3-2) 네이버 뉴스 구조 이해하기 - 섹션별 접속 주소(URL) 확인에서 설명한 코드입니다. 다만, 정치섹션만 확인하기 위해서 주석처리를 해 두었으니, 동작을 확인하신 후에는 정치뿐만 아니라, 경제/사회도 수행해보세요. 25라인에서 <ul>의 class가 "type06_headline"인 것의 <li>를 3개 가지고 옵니다. 26~34라인에서 반복문을 수행하면서, 뉴스 메타 정보를 가져옵니다. 뉴스제목, 날짜, 뉴스 본문, 이미지가 담긴 접속 주소 등의 정보를 가져옵니다.
정말 신기하게도 원하는 결과가 잘 나옵니다.
3-4)gensim으로 뉴스 요약하기
> gensim 라이브러리 설명 : https://radimrehurek.com/gensim/

gensim은 자연어 처리를 하는 라이브러리입니다. 자연어 처리를 지원하는 다양한 함수들이 있으니, 문서를 확인해보세요. 이 장에서는 긴 글을 요약하는 함수만 다루도록 하겠습니다.
긴글을 요약하는 함수는 summarize()라는 함수입니다.
> summarize() 설명 : radimrehurek.com/gensim/summarization/summariser.html

긴글을 text로 주고, 비율(ratio)로 축약을 할 수도 있고, word_count로 축약을 할 수 있습니다.
문서에 설명되어 있는 예시를 보면, 긴 문장이 축약되어 있음을 알 수 있습니다.
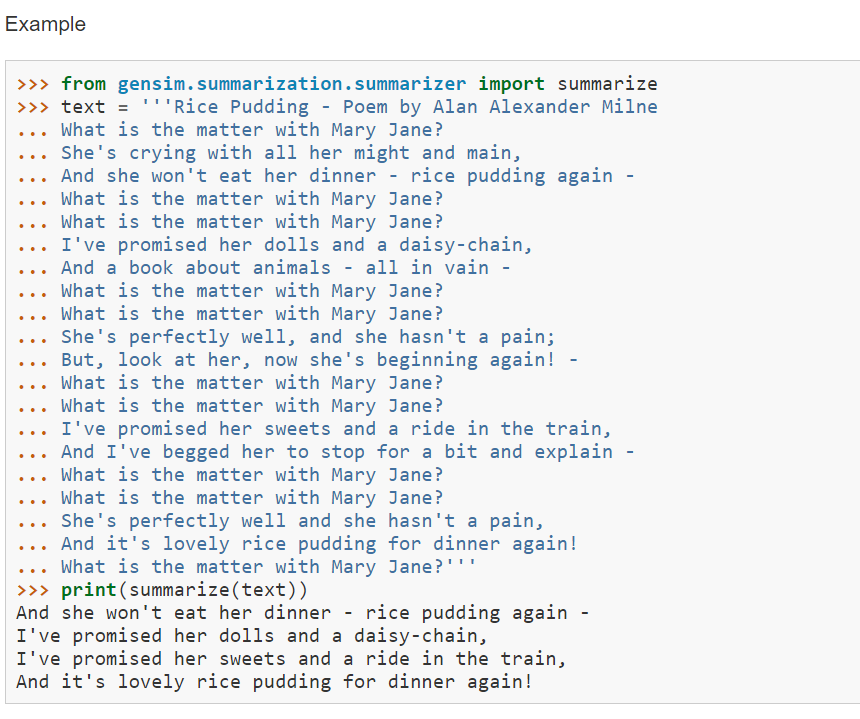
이 함수는 영어뿐만이 아니라, 한국어도 지원이 되니 긴 뉴스 글을 요약할 수 있게 됩니다.
네이버 뉴스 속보의 HTML 구조를 파악하였고, 긴 글을 요약하는 gensim 라이브러리에 대해서 알아보았습니다.
그럼 이제 뉴스를 크롤링하여, 요약하고 그 결과를 카카오톡 메시지를 보내는 뉴스 요약 프로젝트를 쉽게 구현할 수 있겠죠?
4. 구현
구현할 순서는 다음과 같습니다. 네이버 뉴스를 각 섹션별로 크롤링하고, 긴 뉴스 본문을 gensim을 통해 요약을 합니다. 그리고 이 정보를 카카오톡 메시지로 전송합니다.
[구현 순서]
점진적으로 구현을 완성해 갈 수 있도록 Step1 > Step2 > Step3 순서로 진행되며, Step3에서는 소스코드를 완성합니다.
| Step1 | 네이버 뉴스 크롤링 하기 |
| Step2 | 뉴스 요약하기 |
| Step3 | 카카오 메시지 보내기 위한 사전 준비하기 |
| Step4 | 리스트 템플릿으로 뉴스 목록 전송하기 |
| Step5 | 텍스트 템플릿으로 뉴스 요약본 전송하기 |
Step1) 네이버 뉴스 크롤링 하기
코드
import requests
from bs4 import BeautifulSoup
import bs4.element
import datetime
# BeautifulSoup 객체 생성
def get_soup_obj(url):
headers = {'User-Agent' : '<복사한 user-agent값 대체>'}
res = requests.get(url, headers = headers)
soup = BeautifulSoup(res.text,'lxml')
return soup
# 뉴스의 기본 정보 가져오기
# 뉴스의 기본 정보 가져오기
def get_top3_news_info(sec, sid):
# 임시 이미지
default_img = "https://search.naver.com/search.naver?where=image&sm=tab_jum&query=naver#"
# 해당 분야 상위 뉴스 목록 주소
sec_url = "https://news.naver.com/main/list.nhn?mode=LSD&mid=sec" \
+ "&sid1=" \
+ sid
print("section url : ", sec_url)
# 해당 분야 상위 뉴스 HTML 가져오기
soup = get_soup_obj(sec_url)
# 해당 분야 상위 뉴스 3개 가져오기
news_list3 = []
lis3 = soup.find('ul', class_='type06_headline').find_all("li", limit=3)
for li in lis3:
# title : 뉴스 제목, news_url : 뉴스 URL, image_url : 이미지 URL
news_info = {
"title" : li.img.attrs.get('alt') if li.img else li.a.text.replace("\n", "").replace("\t","").replace("\r","") ,
"date" : li.find(class_="date").text,
"news_url" : li.a.attrs.get('href'),
"image_url" : li.img.attrs.get('src') if li.img else default_img
}
news_list3.append(news_info)
return news_list3
# 뉴스 본문 가져오기
def get_news_contents(url):
soup = get_soup_obj(url)
body = soup.find('div', class_="_article_body_contents")
news_contents = ''
for content in body:
if type(content) is bs4.element.NavigableString and len(content) > 50:
# content.strip() : whitepace 제거 (참고 : https://www.tutorialspoint.com/python3/string_strip.htm)
# 뉴스 요약을 위하여 '.' 마침표 뒤에 한칸을 띄워 문장을 구분하도록 함
news_contents += content.strip() + ' '
return news_contents
# '정치', '경제', '사회' 분야의 상위 3개 뉴스 크롤링
def get_naver_news_top3():
# 뉴스 결과를 담아낼 dictionary
news_dic = dict()
# sections : '정치', '경제', '사회'
sections = ["pol", "eco","soc"]
# section_ids : URL에 사용될 뉴스 각 부문 ID
section_ids = ["100", "101","102"]
for sec, sid in zip(sections, section_ids):
# 뉴스의 기본 정보 가져오기
news_info = get_top3_news_info(sec, sid)
#print(news_info)
for news in news_info:
# 뉴스 본문 가져오기
news_url = news['news_url']
news_contents = get_news_contents(news_url)
# 뉴스 정보를 저장하는 dictionary를 구성
news['news_contents'] = news_contents
news_dic[sec] = news_info
return news_dic
# 함수 호출 - '정치', '경제', '사회' 분야의 상위 3개 뉴스 크롤링
news_dic = get_naver_news_top3()
# 경제의 첫번째 결과 확인하기
news_dic['eco'][0]
실행 결과
정치 뉴스 섹션의 첫번째 결과 확인 내용입니다.
{'title': '[그래픽] 미국 대선 승패 핵심 경합주 개표 상황',
'date': '1분전',
'news_url': 'https://news.naver.com/main/read.nhn?mode=LSD&mid=sec&sid1=100&oid=001&aid=0011999084',
'image_url': 'https://imgnews.pstatic.net/image/origin/001/2020/11/07/11999084.jpg?type=ofullfill106_72',
'news_contents': '(서울=연합뉴스) 이재윤 기자 = 미국 대선 승자가 개표 나흘째인 6일(현지시간)까지도 확정되지 않으면서 미국뿐만 아니라 전세계 이목이 네바다, 펜실베이니아 등에 쏠리게 됐다. 이들 주(州)에서는 개표율이 일찌감치 90%를 넘어섰는데도 정작 마지막 남은 몇%를 세는 데 몇날 며칠이 걸리고 있기 때문이다. <저작권자(c) 연합뉴스(https://www.yna.co.kr/), 무단 전재-재배포 금지> '}
코드 설명
1~40 라인 : 3. 사전 지식 쌓기의 '네이버 뉴스 구조 이해하기 - 상위 3개의 뉴스 메타 정보 확인'에서 설명한 부분입니다. 간단하게 정리하면, 필요한 라이브러리를 import 하고, 주어진 url로 beautifulsoup 객체를 return 하는 get_soup_obj()가 있습니다. get_top3_news_info()는 for문의 내용을 함수화 하였습니다. input은 section id, section명을 줍니다. 그러면, url을 구성하고, 상위 3개 뉴스에 대해 메타 정보를 만든 후 output으로 전달합니다.
기존과 다른 점은 28, 38라인의 news_list3 리스트 처리 부분입니다. 3개 뉴스에 대한 메타 정보를 모두 보내줘야 하므로, 리스트 형식으로 만들어 전달합니다.
43~54라인 : 뉴스 본문을 가져오는 get_news_contents()를 정의합니다. input으로는 뉴스 본문이 있는 url을 전달받아, html구조에 맞춰 뉴스 본문을 output으로 전달합니다.
58~81라인 : 3개의 섹션에 대해 top3 뉴스의 메타 정보 및 뉴스 본문을 만드는 get_naver_news_top3() 입니다. input은 없고, output은 3개의 섹션별 3개의 뉴스 정보 및 뉴스 본문을 news_dic을 output으로 전달합니다.
65라인에는 sid에 사용될 정보를 담고, 67라인에서 반복하여 요청합니다. 69라인에서 get_top3_news_info()를 호출하여 top3에 해당하는 뉴스 메타 정보를 얻고, 74라인의 get_news_contents()를 호출하여, 뉴스 본문 정보를 얻습니다.
84라인 : get_naver_news_top3()를 호출하여 섹션별 뉴스 메타 정보, 뉴스 본문을 얻습니다.
86라인 : 얻어진 정보가 정확한지 출력을 통해 확인합니다. 정보가 정확하게 잘 들어왔습니다.

news_dic 구조가 복잡하게 느껴질 수 있어 그림으로 설명하였습니다. 3가지 섹션(정치, 경제, 사회)의 정보가 있고 이는 dictionary형태로 관리가 됩니다. 섹션별 top3 뉴스 메타 정보는 리스트로 구성되어 있고, 리스트 내 각각의 정보는 dictionary 형태로 관리됩니다.
Step2) 뉴스 요약하기
이제 긴 뉴스 본문을 20자 내외로 요약해 봅시다.
코드
from gensim.summarization.summarizer import summarize
# 섹션 지정
my_section = 'eco'
news_list3 = news_dic[my_section]
# 뉴스 요약하기
for news_info in news_list3:
# 뉴스 본문이 10 문장 이하일 경우 결과가 반환되지 않음.
# 이때는 요약하지 않고 본문에서 앞 3문장을 사용함.
try:
snews_contents = summarize(news_info['news_contents'], word_count=20)
except:
snews_contents = None
if not snews_contents:
news_sentences = news_info['news_contents'].split('.')
if len(news_sentences) > 3:
snews_contents = '.'.join(news_sentences[:3])
else:
snews_contents = '.'.join(news_sentences)
news_info['snews_contents'] = snews_contents
## 요약 결과 - 첫번째 뉴스
print("==== 첫번째 뉴스 원문 ====")
print(news_list3[0]['news_contents'])
print("\n==== 첫번째 뉴스 요약문 ====")
print(news_list3[0]['snews_contents'])
## 요약 결과 - 두번째 뉴스
print("==== 두번째 뉴스 원문 ====")
print(news_list3[1]['news_contents'])
print("\n==== 두번째 뉴스 요약문 ====")
print(news_list3[1]['snews_contents'])
실행 결과
경제 섹션 첫번째와 두번째에 해당하는 뉴스기사입니다.
첫번째 뉴스의 내용은 짧아서 요약이 되지 않았고, 두번째 뉴스는 요약이 되었습니다.
==== 첫번째 뉴스 원문 ====
(서울=연합뉴스) 이재윤 기자 = 미국 대선 승자가 개표 나흘째인 6일(현지시간)까지도 확정되지 않으면서 미국뿐만 아니라 전세계 이목이 네바다, 펜실베이니아 등에 쏠리게 됐다. 이들 주(州)에서는 개표율이 일찌감치 90%를 넘어섰는데도 정작 마지막 남은 몇%를 세는 데 몇날 며칠이 걸리고 있기 때문이다. <저작권자(c) 연합뉴스(https://www.yna.co.kr/), 무단 전재-재배포 금지>
==== 첫번째 뉴스 요약문 ====
(서울=연합뉴스) 이재윤 기자 = 미국 대선 승자가 개표 나흘째인 6일(현지시간)까지도 확정되지 않으면서 미국뿐만 아니라 전세계 이목이 네바다, 펜실베이니아 등에 쏠리게 됐다. 이들 주(州)에서는 개표율이 일찌감치 90%를 넘어섰는데도 정작 마지막 남은 몇%를 세는 데 몇날 며칠이 걸리고 있기 때문이다. <저작권자(c) 연합뉴스(https://www
==== 두번째 뉴스 원문 ====
검찰이 월성 1호기 경제성 평가 조작 의혹과 관련해 압수수색에 잇따라 나서자 정치 공방도 뜨거워지고 있습니다. 민주당은 이낙연 대표까지 나서 명백한 정치 수사라고 비판하고 있고 국민의힘은 검찰 흔들기를 중단하라고 반발하고 있습니다. 지난 2018년 6월 조기 폐쇄된 '월성 1호기'는 문재인 정부 핵심 국정과제인 탈원전 정책의 상징이었습니다. [최재형 / 감사원장 (지난달 15일) : 국회 감사 요구 이후에 산업부 공무원들이 관계 자료를 거의 모두 삭제했습니다. 그리고 그것을 복구하는 데도 시간이 걸렸고 또 진술받는 과정에서도 상당히 어려움이 있었습니다.] 최근 검찰이 산업부와 한국수력원자력 등에 대해 이틀에 걸쳐 압수수색을 벌이자 가장 반발한 건 민주당이었습니다. [이낙연 / 더불어민주당 대표(어제 당 최고위원회의) : 검찰이 이제 정부 정책의 영역에까지 영향을 미치겠다는 것으로 해석될 수밖에 없는 것입니다. 이것은 정치 수사이자 검찰권 남용이라고 전 생각합니다.] 윤석열 검찰총장이 대전지검에 방문한 이후 검찰의 압수수색이 시작됐는데, 대전지검 수사 라인이 윤 총장 측근이라는 걸 근거로 들었습니다. [강선우 / 더불어민주당 대변인 : 검찰총장은 자신을 위한 정치가 아닌, 국민을 위한 공정하고 치우침 없는 수사를 하는 자리입니다.] 감사원 감사 결과 경제성 평가 조작 정황이 나왔기 때문에 수사 자체에는 아무런 문제가 없다는 겁니다. 더 나아가 문재인 정부가 추진한 탈원전 정책 자체가 문제라며 핵심 국정 과제에 대한 비판으로 확대할 방침입니다. [주호영 / 국민의힘 원내대표 : 조기 폐쇄의 잘못은 (관련 문서) 444개를 산자부가 파기한 데에서 다 드러났습니다. 뭘 감출 것이 많아서, 무슨 불법이 많아서 그렇게 다 지웠습니까? 탈원전 정책이야말로 대한민국을 자해하는 자해 정책입니다.] 검찰의 수사 대상 자체가 핵심 국정 과제와 관련이 있는 만큼 수사가 진행됨에 따라 공방도 더욱 격화될 것으로 보입니다.
==== 두번째 뉴스 요약문 ====
[이낙연 / 더불어민주당 대표(어제 당 최고위원회의) : 검찰이 이제 정부 정책의 영역에까지 영향을 미치겠다는 것으로 해석될 수밖에 없는 것입니다.
코드 설명
1라인 : 필요한 라이브러리를 import 합니다.
4~5라인 : 정치, 경제, 사회 섹션 중 요약하여 메시지로 받고 싶은 섹션을 지정합니다. 코드에서는 '경제'를 선택하였습니다. 향후 필요에 따라 반복문을 통해 모두 수행해보세요.
11라인 : 긴 뉴스 본문을 20자 정도로 요약하도록 summarize()를 호출합니다. 그런데, 주의 사항이 있는데요. 뉴스의 문장 구성이 10 이하라면, gensim의 summarize()에서 에러를 return 합니다. 에러가 발생하면, python실행이 멈추게 됩니다. 멈추지 않고, 계속 실행될 수 있도록 10~13라인과 같이 try~except 문으로 처리를 합니다.
15~21라인 : summarize()로 처리할 수 없을 경우, 요약문을 대체하고자 합니다. 문장을 분리해서 상위 3개의 문장을 사용하려고 합니다. 문장을 분리하는 방법은 마침표(.)를 사용하면 되겠죠? news_info['news_contents'].split('.')로 뉴스 본문을 마침표(,)로 분리하고 snews_contents = '.'.join(news_sentences[:3])로 상위 3개의 문장을 요약문으로 대체합니다. 그런데, 분리된 문장이 세문장 이상이면 상관없지만 세문장 이하인 경우에는 전체 문장을 요약문으로 사용려고 합니다. 하여, 18라인 처럼 조건문이 들어가 있습니다.
23라인 : 'snews_contents'를 key로 하고, 요약된 문장을 value로 하여 정보를 추가합니다.
이렇게 요약된 뉴스 정보를 카카오 메시지로 보내봅시다.
카카오 메시지 2가지 종류를 보냅니다.
하나는 리스트 템플릿을 사용하여 뉴스 목록을 보내고, 다른 하나는 텍스트 템플릿을 사용하여 뉴스 요약본을 전송합니다.
Step3) 카카오 메시지 보내기 위한 사전 준비하기
카카오 메시지를 보내기 위해서 준비해야 할 사항들이 있습니다.
토큰이 관리되고 있는 파일과 앱키를 준비하고, 유효한 토큰으로 업데이트를 하여 카카오 메시지를 보낼 준비를 하겠습니다.
코드
import json
import kakao_utils
KAKAO_TOKEN_FILENAME = "res/kakao_message/kakao_token.json" #"<kakao_token.json 파일이 있는 경로를 입력하세요.>"
KAKAO_APP_KEY = "<REST_API 앱키를 입력하세요>"
kakao_utils.update_tokens(KAKAO_APP_KEY, KAKAO_TOKEN_FILENAME)
코드 설명
나에게 카톡 메시지 보내기(Link)의 '보충자료' 를 참고합니다.
Step4) 리스트 템플릿으로 뉴스 목록 전송하기
리스트 템플릿으로 뉴스 목록을 구성하여 카카오톡 메시지를 전송해 봅시다.
다소 복잡해 보일 수 있지만, 구성은 이와 같습니다.

코드
# 사용자가 선택한 카테고리를 제목에 넣기 위한 dictionary
sections_ko = {'pol': '정치', 'eco' : '경제', 'soc' : '사회'}
# 네이버 뉴스 URL
navernews_url = "https://news.naver.com/main/home.nhn"
# 추후 각 리스트에 들어갈 내용(content) 만들기
contents = []
# 리스트 템플릿 형식 만들기
template = {
"object_type" : "list",
"header_title" : sections_ko[my_section] + " 분야 상위 뉴스 빅3",
"header_link" : {
"web_url": navernews_url,
"mobile_web_url" : navernews_url
},
"contents" : contents,
"button_title" : "네이버 뉴스 바로가기"
}
## 내용 만들기
# 각 리스트에 들어갈 내용(content) 만들기
for news_info in news_list3:
content = {
"title" : news_info.get('title'),
"description" : "작성일 : " + news_info.get('date'),
"image_url" : news_info.get('image_url'),
"image_width" : 50, "image_height" : 50,
"link": {
"web_url": news_info.get('news_url'),
"mobile_web_url": news_info.get('news_url')
}
}
contents.append(content)
# 카카오 메시지 전송
res = kakao_utils.send_message(KAKAO_TOKEN_FILENAME, template)
if res.json().get('result_code') == 0:
print('뉴스를 성공적으로 보냈습니다.')
else:
print('뉴스를 성공적으로 보내지 못했습니다. 오류메시지 : ', res.json())
실행 결과
'정치' 분야의 뉴스로 구성된 카카오 메시지가 도착했습니다.
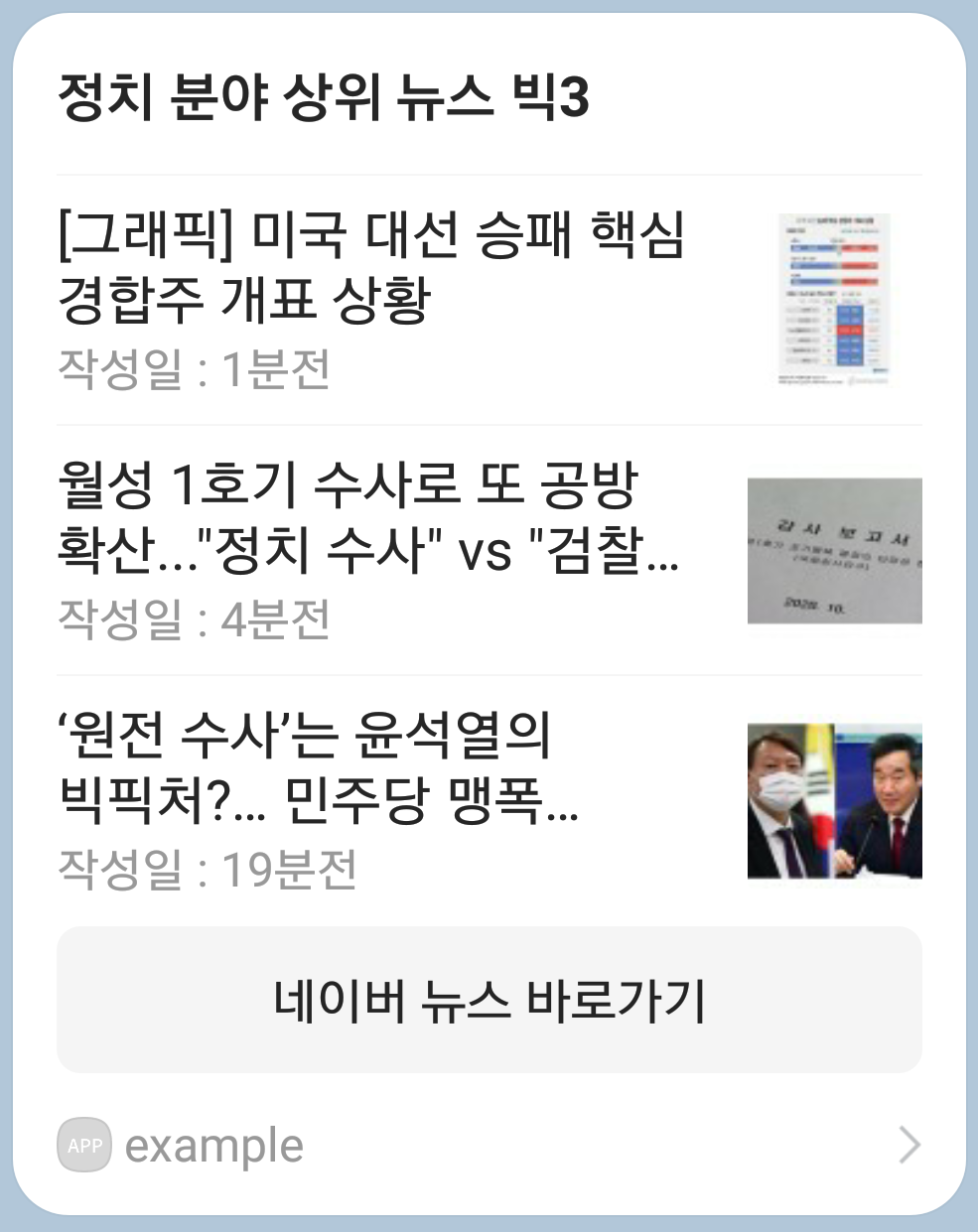
코드 설명
2 라인 : 선택된 섹션에 맞춰 제목인 'OO분야 상위 뉴스 빅3'를 만들기 위한 정보입니다.
5 라인 : 제일 하단 "네이버 뉴스 바로가기" 버튼이 눌러질 경우, 이동할 url 정보입니다. 네이버 뉴스의 홈 화면을 의미합니다.
11~20라인 : 리스트 형태의 템플릿을 만드는 것이므로, 12라인에 "object_type"이 "list"로 되어 있습니다. [그림 15] 리스트 템플릿 구성과 같이 header_title, header_link, button_title정보를 구성합니다.
23~35라인 : 3개의 리스트를 구성할 contents 정보를 구성합니다. [그림 15] 리스트 템플릿 구성과 같이 정보를 구성합니다.
37~42라인 : 카카오 메시지를 보낼 수 있는 REST API 주소와 만들어둔 함수를 호출합니다. 전송 시 에러가 발생한다면, 에러 값을 보고 수정해보세요.
Step5) 텍스트 템플릿으로 뉴스 요약본 전송하기
top3의 뉴스 정보를 요약해서 텍스트 메시지로 전송해 보겠습니다.
템플릿 구성은 다음과 같습니다.

코드
# 3번에 걸쳐 각 뉴스의 요약 결과를 전송합니다
for idx, news_info in enumerate(news_list3):
# 텍스트 템플릿 형식 만들기
template = {
"object_type": "text",
"text": '# 제목 : ' + news_info.get('title') + \
'\n\n# 요약 : ' + news_info.get('snews_contents'),
"link": {
"web_url": news_info.get('news_url'),
"mobile_web_url": news_info.get('news_url')
},
"button_title": "자세히 보기"
}
# 카카오 메시지 전송
res = kakao_utils.send_message(KAKAO_TOKEN_FILENAME, template)
if res.json().get('result_code') == 0:
print('뉴스를 성공적으로 보냈습니다.')
else:
print('뉴스를 성공적으로 보내지 못했습니다. 오류메시지 : ', res.json())실행 결과
아래와 같은 모습의 요약 결과가 담긴 3개의 메시지가 전송되었습니다.
관심 있는 주제라면 "자세히 보기" 버튼을 눌러 뉴스 본문을 확인해 볼 수 있습니다.

코드 설명
2라인 : top3 뉴스이므로 for를 통해 반복합니다.
4~13라인 : [그림 16] 텍스트 템플릿 구성과 같이 템플릿을 구성합니다. 텍스트 템플릿이므로 5라인이 "object_type": "text"로 되어 있습니다.
15~20라인 : 뉴스의 수만큼 반복해서 전송할 것이므로, 반복문 내에서 카카오 메시지를 전송합니다.
5. 요약정리
이번 장에서는 네이버 뉴스를 정치, 경제, 사회 3가지 섹션별로 크롤링하여, 긴 뉴스 본문을 요약하고 그 결과를 카카오 메시지로 보내 보았습니다. 크롤링을 할 때는 URL의 구조 변화와 HTML의 구조를 파악하는 것이 관건이죠? 크롤링에서 제일 중요한 부분이라고 할 수 있습니다. gensim을 사용하여 긴 글을 짧게 요약해보았고, 그 결과를 2가지 형태의 카카오 메시지로 받아 뉴스를 빠르게 읽어 볼 수 있는 프로젝트를 완성하였습니다. 언제 어디서든 빠르게 뉴스 내용을 파악할 수 있겠죠?
도움이 되셨다면, 좋아요 / 구독 버튼 눌러주세요~
저작물의 저작권은 작성자에게 있습니다.
공유는 자유롭게 하시되 댓글 남겨주세요~
상업적 용도로는 무단 사용을 금지합니다.
끝까지 읽어주셔서 감사합니다^^
'오늘 배워 오늘 쓰는 OpenAPI > 프로젝트' 카테고리의 다른 글
| [Python] Selenium 사용법 + 구글 검색 자동화 (11) | 2020.05.16 |
|---|---|
| [Python] Selenium - 동적페이지 크롤링 (2) | 2020.05.16 |
| 웹크롤링 - Beautiful Soup 사용법 + 영화 리뷰 크롤링 (3/3) (13) | 2020.05.09 |
| 웹크롤링 - HTML 이해 (2/3) (1) | 2020.05.09 |
| 웹크롤링 - 웹크롤링 이란? (1/3) (0) | 2020.05.09 |



