
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 업무자동화
- STT
- 구글
- 파이썬간단한게임
- OpenAPI
- 딥러닝
- 파이썬독학
- 구글일정
- 간단한파이썬게임
- 소스코드
- 인공지능
- 기본기
- 파이썬게임
- 음성인식
- 파이썬
- 카카오
- 오늘배워오늘쓰는
- 크롤링
- 머신러닝
- Python
- Ai
- 구글캘린더
- Selenium
- kakao
- 웹크롤링
- 자동화
- Quickstart
- 독학
- 파이썬게임만들기
- 빅데이터
- Today
- Total
ai-creator
[머신러닝 기초] 비전공자도 이해할 수 있는 "머신러닝 개념" 본문

개념
관상, 손금은 어떤 공통점이 있을까?
여러 데이터들을 모아서 그간의 행적을 파악하고, 미래를 예측하는 공통점이 있다.
머신러닝도 마찬가지이다.
과거데이터를 통해 패턴을 파악하고 예측을 하는것이다.
과거 데이터 -> 패턴 파악 -> 예측
이는 마치 함수와 같다. input / process / output 3가지 구성요소를 지닌 함수 말이다.
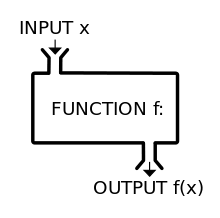
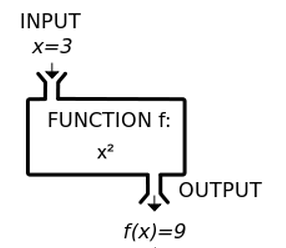
즉
input으로 과거 데이터를
process로는 패턴을 파악하는 연산을
output으로는 예측값을 의미하게 된다.
패턴을 파악하는 연산을 과거에는 인간이 직접하였지만, 이제 이런것은 컴퓨터에게 맡기자!가 머신러닝이라고 생각하면 된다.
패턴 : 인간의 뇌 -> 컴퓨터의 연산
단순히 이야기 하면, 만약 귓볼이 크다면, 복이 있다의 패턴을 if-else 문으로 바꾼거다 라고 생각해도 좋다.
머신러닝 의미를 요약해 보면,
'과거데이터를 사용하여 복잡한 연산으로 그 패턴을 파악한다' 라고 할 수 있겠다.
단점
과거데이터를 가지고 패턴을 만들어 내므로 '데이터 의존적'일 수 밖에 없다.
즉, 우물안개구리 처럼 주어진 세상(데이터)이 전부라고 생각하는 것이다.

그러므로, 편향된 데이터는 편향된 결과를 낳게 된다.
Garbage In Garbage Out
결국 머신러닝에서 데이터는 중요한 역할을 하고 있다. 그렇기 때문에 google, facebook, amazon등의 공룡기업들이 플랫폼처럼 보이지만, 내부에서는 데이터를 소유하려고 노력하고 있다.
오해
회사에서 머신러닝을 도입하겠다! 라고 하면, 머신러닝에 지식이 있지 않으면 도깨비 방망이처럼 인식하는 경향이 있다.

데이터만 넣으면 최적의 결과를 도출할 것이다. 라는 이상한 오해가 난무하다.
하지만, 도메인을 이해하고, 데이터를 가공하고, 최적의 알고리즘을 선택하고, 하이퍼파라메터를 튜닝하는 기나긴 터널을 지나야 만족하는 결과가 나옴을 기억해야 한다.
sckit-learn
파이썬에서는 머신러닝을 쉽게 할 수 있도록 도와주는 패키지가 있다. 데이터과학자라면, 한번쯤 다뤄봤을법한 라이브러리, 바로 sckit-learn(사이킷런, 이하 sklearn)이다.
- (참고) sklearn 문서 : https://scikit-learn.org/stable/
scikit-learn: machine learning in Python — scikit-learn 0.24.2 documentation
Model selection Comparing, validating and choosing parameters and models. Applications: Improved accuracy via parameter tuning Algorithms: grid search, cross validation, metrics, and more...
scikit-learn.org
- cheat sheet : https://s3.amazonaws.com/assets.datacamp.com/blog_assets/Scikit_Learn_Cheat_Sheet_Python.pdf
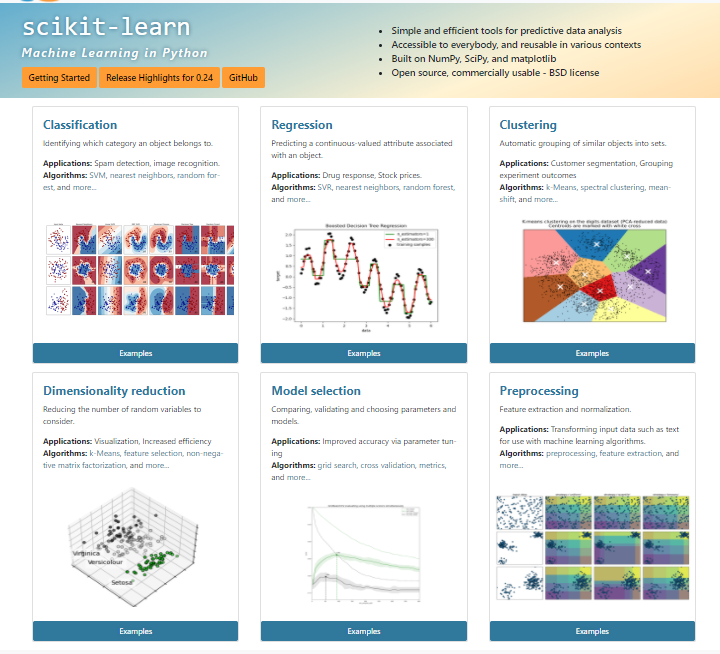
classification, regression, clustering, dimensionality reduction, model selection, preprocessing 등을 지원하고 있다. 즉, 데이터분석, 머신러닝에 필수적인 기능을 제공하고 있는 매우 유용한 패키지 이다.
머신러닝 용어정리
머신러닝을 본격적으로 들어가기 앞서, 처음 배우는 분들을 위해 용어 정리를 해보겠다. 책이나 블로그등을 볼때 같은 의미지만 다른 용어로 사용하는 경우들이 있어 처음에 어려워하는 부분이다. 그래서 어렵진 않지만 헷갈릴수 있는 용어를 정리해보겠다.
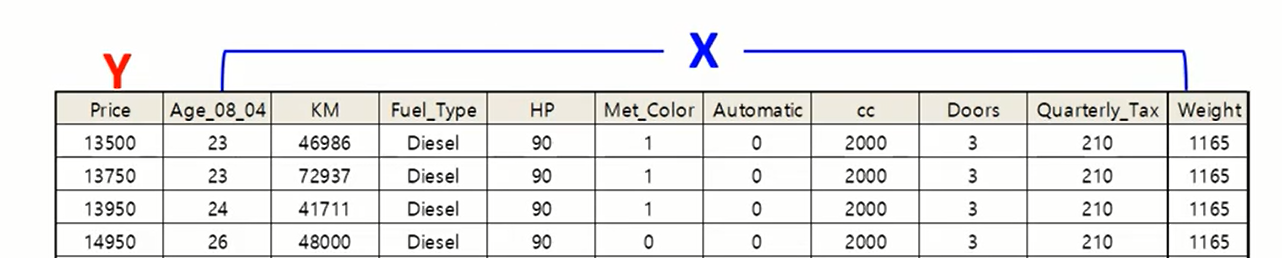
- 종속변수, y, output, target, label, class
: 예측하고자 하는 값을 의미한다.
- 독립변수, x, input, feature, 속성, attribute
: 즉, label 값을 제외한 나머지 데이터를 의미한다.
- 학습(train)
: 머신이 패턴인식을 하는 과정이다.
- 추론(inference), 예측(predict)
: 학습을 기반으로 새로운 데이터의 결과를 알아내는 것이다.
4가지 용어는 함수의 형태와 비슷하다.
input ----> [ 패턴인식을 위한 머신러닝 알고리즘 ] ----> output
input ----> 학습 ----> output
input ----> 추론 ----> output
데이터 전처리(preprocessing)
머신러닝은 패턴을 인식하는 '알고리즘'에 불과하다.
그러나, 우리는 머신러닝을 하기 위해 사전 준비가 필요하다. 어떤 사전 준비? 바로 input에 해당 하는 데이터이다.
데이터를 예쁘게 가공하여, 머신러닝이 패턴을 잘 인식할 수 있도록 해주는 것.
즉, 데이터 전처리가 필수적이다.
머신러닝 알고리즘 종류
머신러닝의 종류는 크게 3가지로 볼 수 있다. Supervised / Unsupervised / Reinforcement
Supervised는 정답이 있는 데이터로 학습을 하고, 미래를 예측하고,
Unsupervised는 정답이 없이 패턴을 인식하여 구조 또는 특징을 발견한다.
Reinforcement는 보상을 통해 최적의 액션을 선택하는 방식이다.

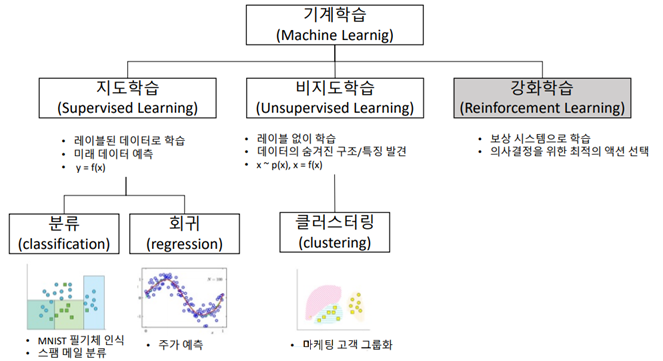
머신러닝 입문시에 제일 먼저 배우는 것은 대체적으로 '지도학습(supervicsed learning)'이다.
다음장에서는
- 지도학습의 완성된 코드를 눈으로 읽어보고,
- '지도학습(supervicsed learning)' 을 위해 무엇을 준비해야 하는지 좀 더 자세히 살펴보겠다.
'데이터 분석 > 왕초보를 위한 머신러닝' 카테고리의 다른 글
| [머신러닝 기초] 다중분류(multi-class) 성능평가 - recall과 precision (0) | 2021.10.16 |
|---|---|
| [머신러닝 기초] 지도학습 - classification 평가척도 (confusion matrix, accuracy, recall, precision, f1-score, ROC, AUC) (0) | 2021.09.25 |
| [머신러닝 기초] 지도학습 - 데이터 전처리 (one-hot encoding, label encoding, Standardization, Normalization) (0) | 2021.09.24 |
| [머신러닝 기초] 지도학습 - 데이터 처리 (학습/테스트 데이터 분리) (1) | 2021.09.24 |
| [머신러닝 기초] 지도학습 - 맛보기 (w/사이킷런) (0) | 2021.09.24 |



