
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 간단한파이썬게임
- 파이썬게임
- 카카오
- Ai
- 음성인식
- 오늘배워오늘쓰는
- 인공지능
- 독학
- 업무자동화
- Selenium
- 웹크롤링
- 파이썬간단한게임
- 구글
- 빅데이터
- Quickstart
- 파이썬게임만들기
- 파이썬독학
- 파이썬
- 소스코드
- 머신러닝
- 구글캘린더
- Python
- 구글일정
- 자동화
- kakao
- 기본기
- 딥러닝
- STT
- 크롤링
- OpenAPI
- Today
- Total
ai-creator
[머신러닝 기초] 지도학습 - 데이터 처리 (학습/테스트 데이터 분리) 본문
이전 포스팅에서 2가지를 언급했다.
1) 머신러닝이란? (Link)
: input ----> [ 패턴인식을 위한 머신러닝 알고리즘 ] ----> output
2) 머신러닝을 도와줄 python 패키지
: Scikit-learn
머신러닝 알고리즘을 사용하기 앞서 해야할 일은 input 가공하는 일이다.
지도학습에 있어 데이터 처리(input가공)는 여러가지가 있다.
이번장에서는
- 학습/테스트를 위한 데이터 분리 및 이에 맞춘 Sklearn API 사용법과 예시를 다뤄보겠다.
이에 대해서 좀 더 자세히 알아보겠다.
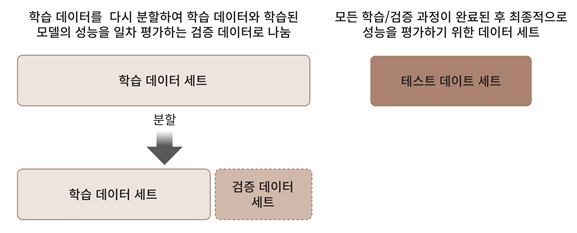
ㅁ 학습/테스트를 위한 데이터 분리
머신러닝에서의 지도학습은 인간의 학습방법과 유사하다.

여기서 머신러닝의 진행 순서를 살펴보자.
"학습 -> 테스트 -> 평가" 이 과정을 반복한다. 원하는 평가가 될때말이다.
그럼 이제 데이터에 집중해보자.
모든 input은 데이터이므로, 학습과 테스트를 하기 위해서는 각기 데이터가 필요하다는걸 알 수 있다.
- train data : label이 포함된 데이터
- test data : label이 포함되지 않은 데이터
학습을 위해서는 train data를 사용하고,
테스트를 위해서는 test data를 사용하게 된다.
머신러닝의 진행 순서를 좀 더 자세히 살펴보면,
데이터를 train용과 test용으로 분리 -> train용 데이터를 input -> 학습 -> test용 데이터를 input -> test -> 예측결과
-> 평가
참고로 평가는 어떻게 하면 될까? 여러분이라면 어떻게 하겠는가?
기계가 예측한 결과와 진짜 정답값을 비교하면 된다.
여기서는 '데이터 처리'에 집중하도록 하자.
데이터를 train용과 test용으로 분리
데이터 분리는 어떻게 할까?
1) 비율로 자르기
의미
제일 간단하게 50:50으로 뚝! 자르면 된다.

그래서 하나는 train용으로 다른 하나는 test용으로 사용하면 된다.
50:50 이라는 비율은 데이터의 크기에 따라 변경될 수 있다. 즉, 룰이 없다는 의미다.
데이터가 적을 경우는 대체적으로 70:30 = train : test의 비율을 사용하고,
요즘과 같은 빅데이터의 경우는 50:50 = train:test 도 사용한다.
Sklearn API
이를 위해 sklearn에서는 API를 지원한다.
| 목적 | import | API |
| 데이터 분리 | from sklearn.model_selection import train_test_split | train_test_split() |
코드에서 보면,
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test=train_test_split(X_titanic_df, y_titanic_df, \
test_size=0.2, random_state=11)데이터 분리 방법은 50:50처럼 단순한 방법을 점점 복잡하게 만든다. 이는 알고리즘에 더 도움이 되도록 말이다.
2) 교차검증(cross validation)
1가지로 고정된 train/test데이터 셋의 경우는 학습 데이터에만 과도하게 최적화되어, 다른 데이터로 실제 예측을 수행할 대 예측 성능이 과도하게 떨어지는 현상이 발생한다.
즉, 이를 "과적합(overfitting)" 되었다고 한다.
이를 피하기 위해 방법들을 소개하겠다.
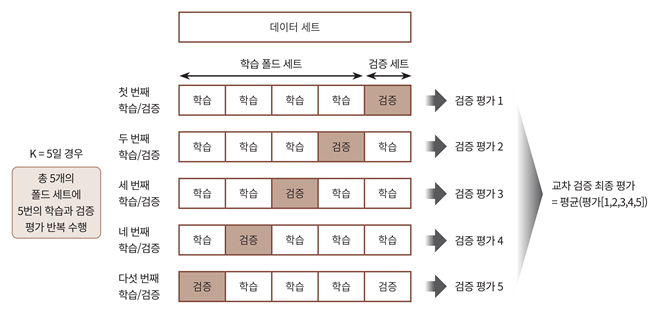
2-1) K-fold 교차 검증
의미
데이터를 K개로 접어서 사용한다고하여, K-fold 교차검증이라고 한다.
5개로 접으면, 5-fold 교차검증이 되는 것이다.
Sklearn API
이를 위해 sklearn에서는 API를 지원한다.
| 목적 | import | API |
| k-fold 교차검증 | from sklearn.model_selection import KFold | KFold() |
코드에서 보면,
# 폴드 세트를 5개인 KFold객체를 생성, 폴드 수만큼 예측결과 저장을 위한 리스트 객체 생성.
kfold = KFold(n_splits=5)
scores = []
# KFold 교차 검증 수행.
for iter_count , (train_index, test_index) in enumerate(kfold.split(X_titanic_df)):
# X_titanic_df 데이터에서 교차 검증별로 학습과 검증 데이터를 가리키는 index 생성
X_train, X_test = X_titanic_df.values[train_index], X_titanic_df.values[test_index]
y_train, y_test = y_titanic_df.values[train_index], y_titanic_df.values[test_index]
# Classifier 학습, 예측, 정확도 계산
clf.fit(X_train, y_train)
predictions = clf.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
scores.append(accuracy)
print("교차 검증 {0} 정확도: {1:.4f}".format(iter_count, accuracy))2-2) Stratified K-fold 교차 검증
의미
sampling 방식을 계층적 방법을 사용하며, 이는 불균형한(imbalanced) 분포도를 가진 레이블(결정 클래스) 데이터 집합에 적합하다.
즉, 현실세계는 데이터의 분포가 불균형한 경우가 더 많다. 예를 들면, 대출 사기를 예측해본다고 가정해보자. 데이터 1억 건 중 대출 사기가 약 1000건 이면 전체의 0.0001%로 사기/정상 레이블 중에서 사기 레이블의 값이 매우 적다는 것을 알 수 있다. 이를 위해 원본 데이터와 유사한 레이블 값의 분포를 학습/테스트 세트에도 유지하는 방법이다.
Sklearn API
이를 위해 sklearn에서는 API를 지원한다.
| 목적 | import | API |
| Stratified k-fold 교차검증 | from sklearn.model_selection import StratifiedKFold | StratifiedKFold() |
코드에서 보면,
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=3)
n_iter=0
for train_index, test_index in skf.split(titanic_df, titanic_df['Survived']):
n_iter += 1
label_train= titanic_df['Survived'].iloc[train_index]
label_test= titanic_df['Survived'].iloc[test_index]
print('## 교차 검증: {0}'.format(n_iter))
print('학습 레이블 데이터 분포:\n', label_train.value_counts())
print('검증 레이블 데이터 분포:\n', label_test.value_counts())데이터 추출 분포를 보면, 대략 3:2 비율을 유지한다는 것을 알 수 있다.
## 교차 검증: 1
학습 레이블 데이터 분포:
0 366
1 228
Name: Survived, dtype: int64
검증 레이블 데이터 분포:
0 183
1 114
Name: Survived, dtype: int64
## 교차 검증: 2
학습 레이블 데이터 분포:
0 366
1 228
Name: Survived, dtype: int64
검증 레이블 데이터 분포:
0 183
1 114
Name: Survived, dtype: int64
## 교차 검증: 3
학습 레이블 데이터 분포:
0 366
1 228
Name: Survived, dtype: int64
검증 레이블 데이터 분포:
0 183
1 114
Name: Survived, dtype: int64
이외에도 sklearn에서는 교차검증을 편리하게 할 수 있는 API를 제공한다.
| 목적 | import | API |
| 교차검증을 편리하게 해줌 | from sklearn.model_selection import cross_val_score | cross_val_score() |
| 교차검증 + 하이퍼파라메터 튜닝으로 최적화함 | from sklearn.model_selection import GridSearchCV | GridSearchCV() |
이에 대해서는 추후에 살펴보도록 하겠다.
이번장에서는 지도학습에 있어 데이터 처리(input가공) 중
- 학습/테스트를 위한 데이터 분리 및 이에 맞춘 Sklearn API 사용법과 예시를 다뤄보았다.
비율로 나누는 방법,
과적합을 막기 위한 교차검증(cross validation) 방법이 있으며,
교차검증에서는 k-fold, stratified k-fold 에 대해서 알아보았다.
ㅁ 추가학습
이번장에서 배운 내용을 iris 데이터를 사용하여 복습해보자.
https://drive.google.com/file/d/1RhEQMTxG03LraIZIz4urI9a1aPm706gA/view?usp=sharing
ㅁ Reference
- [책] 파이썬 머신러닝 완벽가이드
- [블로그] 파이썬 머신러닝 완벽가이드 정리본 (Link)
- [소스코드 출처] : https://github.com/wikibook/pymldg-rev
'데이터 분석 > 왕초보를 위한 머신러닝' 카테고리의 다른 글
| [머신러닝 기초] 다중분류(multi-class) 성능평가 - recall과 precision (0) | 2021.10.16 |
|---|---|
| [머신러닝 기초] 지도학습 - classification 평가척도 (confusion matrix, accuracy, recall, precision, f1-score, ROC, AUC) (0) | 2021.09.25 |
| [머신러닝 기초] 지도학습 - 데이터 전처리 (one-hot encoding, label encoding, Standardization, Normalization) (0) | 2021.09.24 |
| [머신러닝 기초] 지도학습 - 맛보기 (w/사이킷런) (0) | 2021.09.24 |
| [머신러닝 기초] 비전공자도 이해할 수 있는 "머신러닝 개념" (0) | 2021.09.24 |



