
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 오늘배워오늘쓰는
- 소스코드
- 웹크롤링
- 구글
- STT
- 간단한파이썬게임
- 크롤링
- 파이썬게임
- 파이썬간단한게임
- 자동화
- 구글일정
- 음성인식
- 인공지능
- 독학
- 카카오
- 머신러닝
- 빅데이터
- 파이썬게임만들기
- 기본기
- OpenAPI
- 파이썬독학
- 업무자동화
- Selenium
- Ai
- Python
- kakao
- 딥러닝
- 구글캘린더
- 파이썬
- Quickstart
- Today
- Total
ai-creator
[머신러닝 기초] 지도학습 - 데이터 전처리 (one-hot encoding, label encoding, Standardization, Normalization) 본문
[머신러닝 기초] 지도학습 - 데이터 전처리 (one-hot encoding, label encoding, Standardization, Normalization)
ai-creator 2021. 9. 24. 17:13이전 포스팅에서 2가지를 언급했다.
1) 머신러닝이란? (Link)
: input ----> [ 패턴인식을 위한 머신러닝 알고리즘 ] ----> output
2) 머신러닝을 도와줄 python 패키지
: Scikit-learn
머신러닝 알고리즘을 사용하기 앞서 해야할 일은 input 가공하는 일이라고 했으며,
- 학습/테스트를 위한 데이터 분리 및 이에 맞춘 Sklearn API 사용법과 예시를 알아보았다. (Link)
이번장에서는 '기계'가 더 잘 이해할 수 있는 데이터 가공법에 대해서 알아보겠다.
ㅁ 데이터 인코딩 (data encoding)
컴퓨터가 이해하기 위해서는 모든 데이터의 표현이 '숫자'형으로 되어 있어야 한다. 쉽게 풀어서 이야기하면, 텍스트로 이루어진 데이터를 '숫자'로 표현하기를 원한다.
예를 들면, TV, 냉장고, 컴퓨터 (문자형) -> 1, 2, 3 (숫자형) 으로 말이다.
이렇게 숫자로 표현하는 방법은 2가지가 있다.
1) 레이블 인코딩 (label encoding)
2) 원-핫 인코딩 (one-hot encoding)
1) 레이블 인코딩 (label encoding)
의미
레이블인코딩은 카테고리 피처를 숫자 값으로 변환하는 방법이다.
TV, 냉장고, 컴퓨터 (문자형) -> 1, 2, 3 (숫자형)
숫자형이므로 수의 크기가 알고리즘에 작용하여 성능 저하가 될 수 있으니, 주의 해야 한다.
Sklearn API
이를 위해 sklearn에서는 API를 지원한다.
| 목적 | import | API |
| 레이블 인코딩 | from sklearn.preprocessing import LabelEncoder | LabelEncoder() |
코드에서 보면,
from sklearn.preprocessing import LabelEncoder
items=['TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서']
# LabelEncoder를 객체로 생성한 후 , fit( ) 과 transform( ) 으로 label 인코딩 수행.
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
print('인코딩 변환값:',labels)코드 수행 결과
인코딩 변환값: [0 1 4 5 3 3 2 2]2) 원-핫 인코딩 (one-hot encoding)
의미
레이블 인코딩의 단점을 보완하기 위해, 각 카테고리를 input feature로 구성되는 방법이다. 값은 해당하는 칼럼에만 1, 나머지 칼럼에는 0을 표시하게 된다.

Sklearn API
이를 위해 sklearn에서는 API를 지원한다.
| 목적 | import | API |
| 원-핫 인코딩 | from sklearn.preprocessing import OneHotEncoder | OneHotEncoder() |
코드에서 보면,
from sklearn.preprocessing import OneHotEncoder
import numpy as np
items=['TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서']
# 먼저 숫자값으로 변환을 위해 LabelEncoder로 변환합니다.
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
# 2차원 데이터로 변환합니다.
labels = labels.reshape(-1,1)
# 원-핫 인코딩을 적용합니다.
oh_encoder = OneHotEncoder()
oh_encoder.fit(labels)
oh_labels = oh_encoder.transform(labels)
print('원-핫 인코딩 데이터')
print(oh_labels.toarray())
print('원-핫 인코딩 데이터 차원')
print(oh_labels.shape)코드 수행 결과
원-핫 인코딩 데이터
[[1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 1.]
[0. 0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0. 0.]
[0. 0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0. 0.]]
원-핫 인코딩 데이터 차원
(8, 6)원-핫 인코딩에 있어 sklearn API의 단점은 반드시 label encoding을 통해 숫자형으로 변환한 후 one-hot encoding을 해야 한다는 번거로움이 있다. 하여, 동일한 동작을 하는 pandas 라이브러리를 더 많이 사용한다.
import pandas as pd
df = pd.DataFrame({'item':['TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서'] })
pd.get_dummies(df)코드 수행 결과

ㅁ 피쳐 스케일링
피처 스케일링(feature scaling)이란? 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업을 의미한다.
표준화(standardization)와 정규화(Normalization)가 있으며, 각 의미는 아래와 같다.
1) 표준화 : 데이터의 피처 각각이 평균이 0이고, 분산이 1인 표준 정규 분포(standard normal distribution)로 변환하는 것을 의미
2) 정규화 : 서로 다른 피처의 크기를 통일하기 위해 그 크기를 변환해 주는 개념

1) 표준화(Standardization)
의미
데이터의 피처 각각이 평균이 0이고, 분산이 1인 표준 정규 분포(standard normal distribution)로 변환하는 것을 의미한다.

평균이 0이고, 분산이 1인 정규분포(normal distribution)를 표준 정규 분포(standard normal distribution)라고 칭한다.
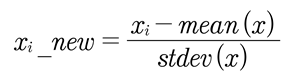
특정 알고리즘은 데이터의 분포를 가정한 경우가 있다. 서포트 벡터 머신, 선형 회귀, 로지스틱 회귀 등 가우시안 분포를 가정하고 있어, 데이터를 표준화시켜 예측 성능 향상시킬 수 있다.
Sklearn API
이를 위해 sklearn에서는 API를 지원한다.
| 목적 | import | API |
| 표준화 | from sklearn.preprocessing import StandardScaler | StandardScaler() |
코드에서 보면,
from sklearn.datasets import load_iris
import pandas as pd
# 붓꽃 데이터 셋을 로딩하고 DataFrame으로 변환합니다.
iris = load_iris()
iris_data = iris.data
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
print('feature 들의 평균 값')
print(iris_df.mean())
print('\nfeature 들의 분산 값')
print(iris_df.var())
##################################################################
from sklearn.preprocessing import StandardScaler
# StandardScaler객체 생성
scaler = StandardScaler()
# StandardScaler 로 데이터 셋 변환. fit( ) 과 transform( ) 호출.
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
#transform( )시 scale 변환된 데이터 셋이 numpy ndarry로 반환되어 이를 DataFrame으로 변환
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns=iris.feature_names)
print('feature 들의 평균 값')
print(iris_df_scaled.mean())
print('\nfeature 들의 분산 값')
print(iris_df_scaled.var())코드 수행 결과
feature 들의 평균 값
sepal length (cm) 5.843333
sepal width (cm) 3.054000
petal length (cm) 3.758667
petal width (cm) 1.198667
dtype: float64
feature 들의 분산 값
sepal length (cm) 0.685694
sepal width (cm) 0.188004
petal length (cm) 3.113179
petal width (cm) 0.582414
dtype: float64
feature 들의 평균 값
sepal length (cm) -1.690315e-15
sepal width (cm) -1.637024e-15
petal length (cm) -1.482518e-15
petal width (cm) -1.623146e-15
dtype: float64
feature 들의 분산 값
sepal length (cm) 1.006711
sepal width (cm) 1.006711
petal length (cm) 1.006711
petal width (cm) 1.006711
dtype: float64feature들의 평균과 분산값이 0, 1로 수렴하는 것을 볼 수 있다.
2) 정규화(Normalization)
의미
서로 다른 피처의 크기를 통일하기 위해 그 크기를 변환해 주는 개념이다.
예를 들어 피처A는 거리를, 피처B는 금액을 나타낼때, 모두 동일한 크기 단위로 비교하기 위해 값을 모두 0~1 또는 -1~1의 범위를 갖도록 만드는 것이다.
다양한 정규화 방법이 있으며, 여기서는 Min/Max Scaler만 언급하겠다.
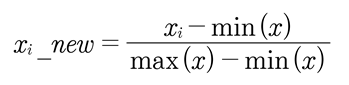
Sklearn API
이를 위해 sklearn에서는 API를 지원한다.
| 목적 | import | API |
| min/max 정규화 | from sklearn.preprocessing import MinMaxScaler | MinMaxScaler() |
코드에서 보면,
from sklearn.preprocessing import MinMaxScaler
# MinMaxScaler객체 생성
scaler = MinMaxScaler()
# MinMaxScaler 로 데이터 셋 변환. fit() 과 transform() 호출.
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
# transform()시 scale 변환된 데이터 셋이 numpy ndarry로 반환되어 이를 DataFrame으로 변환
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns=iris.feature_names)
print('feature들의 최소 값')
print(iris_df_scaled.min())
print('\nfeature들의 최대 값')
print(iris_df_scaled.max())코드 수행 결과
feature들의 최소 값
sepal length (cm) 0.0
sepal width (cm) 0.0
petal length (cm) 0.0
petal width (cm) 0.0
dtype: float64
feature들의 최대 값
sepal length (cm) 1.0
sepal width (cm) 1.0
petal length (cm) 1.0
petal width (cm) 1.0
dtype: float64모든 feature의 값들의 최소~최대 범위가 0~1이 되었음을 알 수 있다.
이번장에서는 "'기계'가 더 잘 이해할 수 있는 데이터 가공법"에 대해서 알아보았다.
- 카테고리형 변수를 숫자형으로 변경해주는 encoding 방법이 있었고
label encoding, one-hot encoding에 대해서 알아보았다.
- 데이터의 분포와 범위를 일정 수준으로 맞추는 피처스케일링이 있었고
표준화, 정규화에 대해서 알아보았다.
다음장에서는 지도학습을 '평가'하는 방법에 대해서 알아보겠다.
ㅁ 추가학습
아래 블로그에서 목표로 잡았던, ' titanic 데이터를 이용하여 생존여부를 예측하는 코드를 이해'해 본다.
https://ai-creator.tistory.com/574?category=875603
[머신러닝 기초] 지도학습 - 맛보기 (w/사이킷런)
최종 목표 지도학습에서 최종목표는 titanic 데이터를 이용하여 생존여부를 예측하는 코드를 이해하는 것이다. 코드 이해에 있어 - 지도학습 수행을 위한 프로세스를 이해한다. - 프로세스의 각
ai-creator.tistory.com
ㅁ Reference
- [책] 파이썬 머신러닝 완벽가이드
- [블로그] 파이썬 머신러닝 완벽가이드 정리본 (Link)
- [소스코드 출처] : https://github.com/wikibook/pymldg-rev
'데이터 분석 > 왕초보를 위한 머신러닝' 카테고리의 다른 글
| [머신러닝 기초] 다중분류(multi-class) 성능평가 - recall과 precision (0) | 2021.10.16 |
|---|---|
| [머신러닝 기초] 지도학습 - classification 평가척도 (confusion matrix, accuracy, recall, precision, f1-score, ROC, AUC) (0) | 2021.09.25 |
| [머신러닝 기초] 지도학습 - 데이터 처리 (학습/테스트 데이터 분리) (1) | 2021.09.24 |
| [머신러닝 기초] 지도학습 - 맛보기 (w/사이킷런) (0) | 2021.09.24 |
| [머신러닝 기초] 비전공자도 이해할 수 있는 "머신러닝 개념" (0) | 2021.09.24 |



